Je suis heureux d’annoncer la publication d’un de mes textes intitulé Éléments pour une analyse juridique du numérique dans les actes du colloque de la 4e et 5e Journées d’étude sur la méthodologie et l’épistémologie juridiques. Grâce à une licence d’édition permissive de la part de l’éditeur (Éditions Yvon Blais), j’ai pu verser mon texte dans l’archive ouverte de mon institution, Spectrum de l’Université Concordia.
Voici la référence complète:
Charbonneau, Olivier (2016) Éléments pour une analyse juridique du numérique. In: Les nouveaux chantiers de la doctrine juridique : Actes des 4e et 5e Journées d’étude sur la méthodologie et l’épistémologie juridiques. Éditions Yvon Blais, Montréal, pp. 459-479. ISBN 978-2-89730-274-0
Détail intéressant, je me suis donné un défi de taille pour ce texte : le préparer en suivant les préceptes de la science ouverte autant que possible. Ainsi, j’ai capté la conférence où j’ai présenté la première version et j’ai inclus la vidéo dans mon blogue. Ensuite, j’ai écrit et diffusé la version « pré-éditée » (avant l’envoi au processus de révision) sur cette page de mon carnet. Finalement, la version éditée est consignée dans le dépôt institutionnel de l’Université Concordia, mon employeur. Il ne manque que les commentaires des réviseurs (en fait, je n’ai pas vraiment reçu de commentaires sur le fond de mon écrit).
Je vous offre donc la vidéo de ma conférence liée à cet écrit:
Les listes de diffusion par courriel sont à la fois une panacée et une épine dans le pied. D’un côté, il s’agit d’un tamtam virtuel à portée d’oreille d’une communauté de pratique qui constitue un réseau fort de cerveaux. De l’autre, ces listes sont parfois une source intarissable de pourriels. La patience est de mise lorsqu’on se gargarise de ce panaché mi-figue ni-raisin numérique…
(Ok, désolé pour toutes ces métaphores croisées, je vais blâmer cette petite neige sur Montréal pour mon « inspiration »)
Je viens de vivre un ce des moments magiques. Une question lancée sur la liste des membres de Humanistica, l’association francophone des humanités numériques/digitales, et hop, les échangent fusent. La question est pertinente, je dois avouer y avoir consacré quelques moments, aidant un collègue à se battre avec un tableur Excel pour effectuer une analyse bibliographique de listes de références. Enfin, il a publié son texte dans une revue savante:
Mais je me suis toujours demandé s’il y avait un meilleur outil qu’Excel. C’est pourquoi j’ai lu les courriels diffusés sur la liste d’Humanistica avec attention et je vous offre un sommaire des échanges ici-bas.
(Soit dit en passant: pour respecter le droit à l’anonymat des intervenants sur la liste, je me réserve le droit de taire leur identité. Par ailleurs, j’ai recours aux dispositions sur l’utilisation équitable de la Loi sur le droit d’auteur du Canada, pour des fins de critique et de compte rendu, pour diffuser le contenu desdits courriels. Si vous avez participé à l’échange et que ce billet vous pose problème, n’hésitez pas à me contacter! Je partage pour le bien de la communauté scientifique francophone étendue.)
Le cas est bien connu. Vous disposez d’une série de textes, dont chacun comporte une bibliographie. Le nombre de textes importe peu – il peut en avoir 5 ou 500. L’idée est que vous voulez analyser ou fouiller lesdites bibliographies de chacun des textes afin d’en extraire une forme d’intelligence: quels auteurs sont les plus cités? Quelles revues ou sources? Y a-t-il des sujets plus présents? Etc.
Le défi est simple. Il faut tenir compte de deux « niveaux » bibliographique. D’une part, le texte « principal ». De l’autre, sa bibliographie. Dans les deux cas, il est désirable de revenir le même format de données, la référence bibliographique, car les deux classes de documents partagent le même dictionnaire de données.
Il s’agit exactement des besoins de mon collègue et nous avons utilisé Excel par simplicité (nous avions déjà ce logiciel d’installé sur nos ordinateurs). Dans Excel, mon collègue a simplement consigné les données, puis nous avons créé un index central de tous les textes. Nous avons « nettoyé » les données avec certaines fonctions d’Excel, tels text to columns, pour transformer les données textuelles de chaque item dans la liste de référence en données un peu plus structurées. Ensuite, nous avons utilisé des fonctions de recherche, tels vlookup et count, pour créer des statistiques. Ceci dit, nous avons eu recours à des compilations manuelles (trop souvent) pour atteindre les objectifs de recherche.
Je suis ravi de savoir qu’il existe de meilleurs moyens d’atteindre cet objectif. Voici, en séquence, les outils qui furent évoqués sur la liste, dont j’ai nettoyé et allégé le texte:
Grobid https://github.com/kermitt2/grobid, dont le but est justement d’extraire des informations structurées de publications scientifiques.
D’ailleurs, Sean Takats précise ce qui suit: « Paper Machines: le projet est abandonné; en plus il n’aurait pas résolu le problème de suivre l’évolution des références dans les publications scientifiques. »
Sean Takats poursuit: « Si les publications ont des bibliographies, on peut se servir du site https://anystyle.io (créé par l’un des développeurs actuels des projets Zotero et Tropy). Après l’extrait des références, on pourrait les analyser même dans une feuille de calcul — un corpus de 27 documents est assez petit et n’exige pas franchement la fouille de texte. Si vous voulez vraiment faire du text mining avec vos documents, le logiciel gensim (https://pypi.python.org/pypi/gensim) marche bien avec des données en français. (paragraphe) En principe on pourrait tirer les références Zotero directement des documents mais la fonction n’existe pas encore (https://github.com/zotero/zotero/issues/21)
En complément, une collègue propose quelques pistes additionnelles :
Vosviewer : software tool for constructing and visualizing bibliometric networks http://www.vosviewer.com/
http://www.qiqqa.com un outil doté d’un moteur de recherche sémantique puissant (thèmes, autotags…), annotation de document, lien avec BibteX, Word (mode gratuit limité).
Si vos [publications] sont dans Scopus, la fonction analyze results , ou Cited by permet de répondre à certaines de vos questions.
Bonne extraction de données bibliographiques!
P.S.: Je rêve du jour où l’on pourra naviguer sur des vagues de références bibliographiques pour découvrir les contours de champs disciplinaires… Imaginez: vous choisissez un sujet, disons l’inclusion de jeux vidéo en bibliothèque, et à partir de quelques textes savants, vous pouvez bâtir un réseau de citation dynamique et filtrer l’inclusion ou l’exclusion de textes. Cet outil pourrait être le système par lequel les étudiants du premier cycle universitaire découvrent un domaine (voire, préparent les travaux de session d’un cours) et les étudiants au deuxième cycle peaufinent leur compréhension de leur discipline.
Les outils évoqués dans ce billet en sont le début, en plus des outils commerciaux comme Web of Science, démontrent les balbutiements d’un web sémantique scientifique. Il faut oeuvrer vers des données bibliographiques liées, un chantier encore largement inachevé qui nécessite la participation d’une foule institutions vers un but commun…
L’ironie est que le milieu des bibliothèques doit composer avec l’accès ou la diffusion libre de ressources… Cette nouvelle pratique, découlant de l’édition traditionnelle, offre aux communicants l’opportunité de disséminer leurs propres créations directement. L’apport des bibliothèques, quant aux pratiques d’acquisition documentaires, constitue un filtre qui peut offrir un moyen de mesurer avec une certaine impartialité l’impact relatif d’une oeuvre. C’est d’ailleurs l’approche de la Commission du droit de prêt public du Canada, qui base la distribution de ses fonds aux auteurs du pays sur la base de la présence de leurs livres en bibliothèques publiques. L’ironie survient de la gratuité : dépenser de l’argent public suppose un effort professionnel diligent et raisonnable.
Une ressource gratuite donc, peu importe le domaine, se perd dans la masse du web et ne s’incorpore pas dans les processus d’acquisition des bibliothèques. C’est dommage, tragique même, d’autant plus que dans certains contextes des agents sociaux se coordonnent pour créer des ressources libres vraiment intéressantes. Le droit est un de ces domaines.
Outre les sites Éducaloi ou Jurisource, voire CanLII, j’ai le plaisir de vous présenter le projet ADAJ.ca, une initiative de professeur Pierre Noreau du Centre de recherche en droit public de l’Université de Montréal. L’ADAJ vise à favoriser l’accès au droit et à la justice en regroupant une panoplie de partenaires autour de 20 chantiers, un véritable catalogue des idées de réforme du droit. Voici une courte présentation du projet ADAJ:
Donc, le domaine du droit est un bel exemple des mutations découlant du processus socioéconomiques de la création et de la diffusion de l’information. Ces réifications, induites par le numérique, introduisent de nouveaux modèles, dont celui de l’accès libre. Les institutions doivent réagir à ces changement dans leur environnement externe en réfléchissant à de nouveaux modèles…
Il y a quelques temps, j’ai eu l’incroyable chance de discuter avec un doctorant sur les outils technologiques pertinents pour effectuer une analyse textuelle et en réseau. Je vous propose les notes résultant de cette conversation, sans préciser que les éléments ci-dessous sont les meilleurs ou les plus pertinents. Il s’agit d’une liste d’outils proposés lors de l’exploration de son approche pour sa recherche.
En premier lieu, il recommande l’outil CAT Scanner pour effectuer une première analyse d’une série de documents en formats PDF, qu’ils soient à base textuelle ou un « PDF image » – ledit logiciel effectue la reconnaissance de caractères (OCR) et des dénombrements simples.
Ensuite, il a retenu le logiciel LIWC – Linguistic Inquiry and Word Count pour pousser l’analyse textuelle. Ce système permet la création de dictionnaires personnels ou d’avoir recours à des dictionnaires pré-définis. Par exemple, plusieurs chercheurs ont déjà étudier les corpus linguistiques d’un domaine affectif ou de la connaissance et il est possible d’utiliser ces bases de termes pour effectuer des analyses comparatives. En particulier, il m’a mentionné les travaux de Holsti qui, en 1969, a validé un dictionnaire précis pour le domaine des sciences humaines et social dans son étude intitulée Content Analysis for the Social Sciences. Le dictionnaire de Holsti fut utilisé dans bon nombre d’études et fut traduit en quelques langues, dont le français. Ce genre d’outil est particulièrement pertinent pour les études de la couverture média sur des sujets ou des entreprises.
Il existe plusieurs autres outils pour effectuer une analyse textuelle tels Nvivo ou Atlas. Par ailleurs, d’autres systèmes permettent l’analyse en réseau (network Analysis), tels R, Gephy, Cytoscape, Stata ou SPSS (tout dépend de comment nous utilisons ces outils).
Sur un autre ordre d’idée, je veux également mentionner d’autres sources pertinentes que j’ai accumulé ces dernières semaines…
Il y a Sémanto de l’UQAM qui permet d’effectuer des analyses textuelles à partir de sondages web.
Je vous propose ici quelques réflexions et lectures concernant le droit d’auteur dans les bibliothèques. Je vais intervenir dans le cours de Marie Demoulin à l’EBSI ce vendredi et, fidèle à mon habitude, je consigne mes notes ici.
Avant de poursuivre, j’ai une série de billets sur le sujet du droit d’auteur sur mon carnet outfind.ca (en anglais) que j’utilise dans le cadre de mes interventions à l’Université Concordia (mon employeur – les cours s’y donnent en anglais j’ai donc besoin d’un carnet dans cette langue aussi). Si vous avez soif pour plus, jetez-y un coup d’oeil…
1. Le droit d’auteur, du point de vue institutionnel, découle d’un choix
J’entend souvent dire que le droit d’auteur est un sujet complexe. En réalité, la complexité découle du fait que nous avons perdu nos repères traditionnels à cause de l’avènement du numérique. Nous devons revisiter les prémisses de nos pratiques professionnelles découlant de l’ère « papier » pour les appliquer à l’environnement numérique et au contexte juridique actuel. La complexité ne découle pas du grand nombre d’options quant au respect du droit d’auteur mais d’une absence de moyen pour opérer un choix. D’ailleurs, ce choix ce fait traditionnellement en réseau et notre milieu souffre d’un éparpillement associatif.
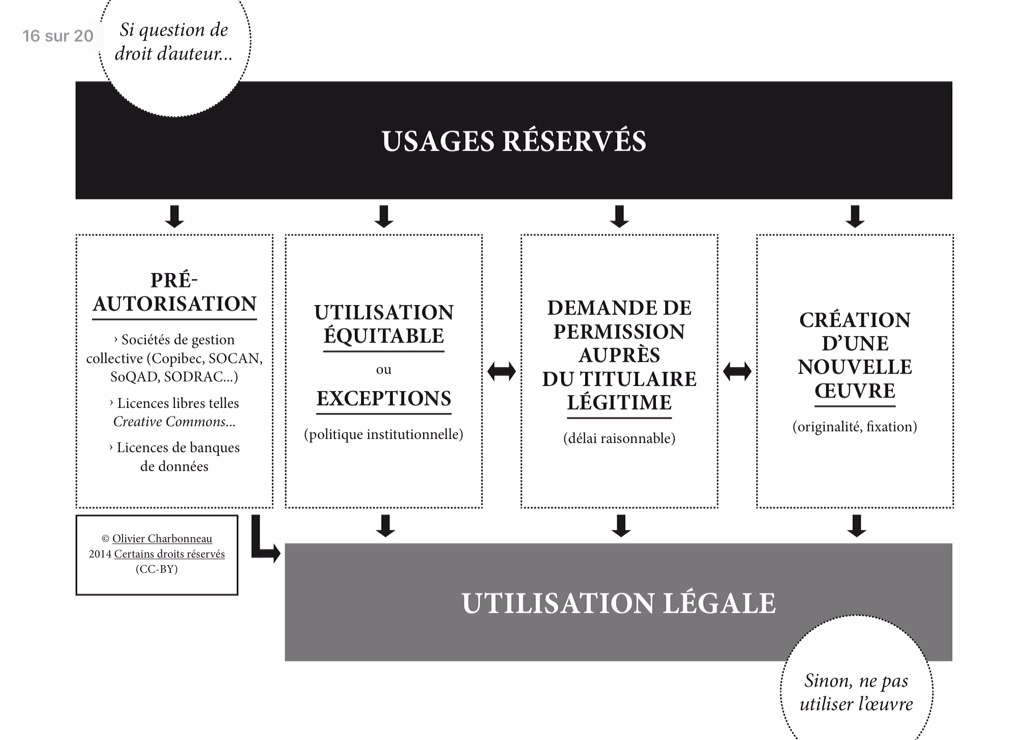
J’ai eu la chance de réfléchir aux choix en lien avec le droit d’auteur à travers le Chantier sur le droit d’auteur en milieu scolaire . J’ai épaulé des collègues chevronnée qui ont bâti un outil pour appréhender le système du droit d’auteur : cette réflexion nous a mené à proposer une Foire aux questions sur le droit d’auteur en milieu scolaire de l’Association pour l’avancement des sciences et techniques de la documentation en milieu scolaire (APSDS). Je vous propose ce graphique qui explique sommairement les choix qui découlent au droit d’auteur :
2. Le choix doit s’opérer selon une matrice oeuvre-utilisation
Je manque de temps pour expliquer cette idée, mais constatez comment nous avons organisé notre travail dans la Foire aux questions de l’APSDS – nous avons pris des classes de documents et nous avons effectué un remu-méninges pour lister tous les contextes d’utilisation. Ainsi, nous avons établi une « matrice » oeuvre-utilisation, où les lignes sont les classes de documents et où les colonnes sont les types d’utilisation. Pour chaque « cellule » ou instance oeuvre-utilisation, nous avons déterminé lequel des choix nous devons opérer pour atteindre une utilisation légale.
C’est un peu la recette de ma sauce secrète que j’utilise à chaque fois que je travaille avec une question de droit d’auteur.
J’explore depuis un certain temps les thèmes de la jurilinguistique et, plus largement, la diffusion numérique du droit. J’ai regroupé ces billets sous les mots-clic « réseaux » ainsi que « dictionnaires« . Dans ce contexte, je songe de plus en plus au thème des méthodes quantitatives en droit, appliquées à des corpus documentaires numériques. Une chercheure chevronnée et amie m’a suggéré la lecture du texte suivant, et je vous propose ensuite mes notes de lecture (une sorte de sommaire personnel et intéressé).
BOUCHARD, V., «Collecte des données et approches critiques du droit: du trop peu au trop grand» dans AZZARIA, G. (dir.), Les cadres théoriques et le droit : actes de la 2e Journée d’étude sur la méthodologie et l’épistémologie juridiques, Cowansville, Québec, Éditions Y. Blais, 2013, p. 381-406
Globalement, Bouchard analyse puis critique certains systèmes de repérage des sources du droit, en proposant un début de critique qui prend racine dans le féminisme et l’approche critique du droit (de l’école réaliste américaine).
Dans son texte, Bouchard pose la question suivante: «comment pouvoir aspirer à la critique du droit sans une recherche critique ? Notre façon de faire mène presque inéluctablement à une herméneutique, déguisée ou avouée, des sources normatives du droit (p. 382).»
Puis,
«La collecte des données est un moment de la recherche dont l’importance et la portée sont oblitérées. Je profite de cette affirmation pour préciser qu’il ne s’agit pas ici de faire l’apologie tyrannique de l’empirisme juridique ou de la théorie ancrée (grounded theory). La diversité de l’information et la conscience de l’information ne privent pas de faire une recherche métaphysique ou herméneutique, etc. Chaque méthode a sa vertu; il s’agit cependant de prendre conscience de notre manière de colliger la matière première de nos recherches et de tenter de la désenclaver, si la nature de notre recherche le commande (p. 382)»
Bouchard identifie que sa problématique découle d’une certaine fermeture de la communauté juridique.
«En définitive, in semble que la communauté juridique ne souhaite pas embrasser, de manière utile ou structurée, les nouvelles sources d’information disponibles. La littérature scientifique relative à ces problématiques demeure généralement liée aux préoccupations des sciences archivistiques et s’est ainsi particulièrement concentrée sur les enjeux de la conservation de la documentation en ligne. Aux fins de ce texte, je m’intéresserai donc à ces initiatives d’archivage et aux réflexions auxquelles elles donnent lieu (p. 389).»
Conséquemment,
Bouchard cite, à l’occurence, «l’importance de l’autorité et qui se construit en partie sur une hiérarchie normative des sources (p. 389)» pour expliquer la réticence d’avour recours à des sources diffusées dans Intenret. La chercheure offre l’index suivant des propositions qui structurent son texte:
1. Les bases de données de nature encyclopédique sont un construit idéologique;
2. Les bases de données juridiques sont un construit idéologique et positiviste;
3. Les données disponibles sur Internet peuvent constituer une voie alternative: les élections iraniennes de 2009 et Michael Geist;
4. Internet est un «réservoir documentaire planétaire»* faisant face à l’oubli, quelques initiatives de préservation: Internet Archive et Kulturarw3 Project;
5. Internet est un trop grand réservoir documentaire, quelques initiatives de mémoire sélective: WAX;
6. Internet est un réservoir de documents liés, une considération qui nous ramène au début de la liste;
7. Conclusion: la Vatican et Foucault chirurgien.
(p. 384)
* citant: Aìda Chebbi, «Archivage du web: quelques leçons à retenir», (2007-2008) 39:2 Archives 19, 19.
Pour les deux premières propositions de son argumentaire, Bouchard offre une critique du répertoire de vedettes matières (qui est une traduction faite par nos collègues de l’Université Laval des Library of Congress Subject Headings) sur les facettes attribuées à deux documents précis. Elle y note l’absence de référence au cadre d’analyse critique ou féministe des études indexées dans l’attribution des facettes. Elle déplore ce construit social et idéologique qui limite l’accès à ces documents sur ce plan.
Dans sa troisième section, Bouchard propose que certains corpus découlant de systèmes nouveaux offrent des opportunités d’effectuer des études en droit. Elle offre deux exemples: les gazouillis échangés en anglais par la diaspora iranienne concernent les élections nationales en 2009; ainsi que le blogue de Michael Geist. Pour ce dernier exemple, elle se questionne sur l’apport des blogueurs juridiques dans la diffusion sociale du droit.
Bouchard propose son cadre d’analyse dans la quatrième proposition. Ainsi, la documentation numérique, comme les autres systèmes documentaires qui la précède, imposent de «circonscrire les limites du document» (p. 394) qui ne sont pas des «objets indépendants, finis et déterminés» (p. 394) malgré que l’on les considèrent souvent comme tels; «cela malgré la découverte de l’intertextualité!» (p. 394). L’exemple de la citation offre à Bouchard l’occasion de démontrer la dichotomie entre l’aspect finit d’un texte et sa composition en fragments d’autres textes.
«La documentation en ligne n’échappe pas totalement à ces réflexes. Il faut cependant constater, sans applaudir une révolution, que les possibilités du numérique marquent la documentation qu’il supporte de trois nouvelles caractéristiques, lesquelles ont une influence sur les possibilités de préservation et d’accès (voire d’étude): la connectivité, l’abolition des notions de temps et d’espace et l’interactivité*. La connectivité souligne l’intertextualité des discours. […] De la même manière, la nature virtuelle de la documentation en fait un objet volatile et flou. […] Enfin, l’interactivité de l’information masque la frontière entre les actes d’écrire et de lire.» (p. 394-5)
* Citant Chebbi.
Ainsi, l’existence des documents virtuels seraient menacés par leurs caractéristiques (p. 395). Les projetsInternet Archive et Kulturarw3 Project sont des initiatives qui tentent de renverser la donne d’un point de vue exhaustif. Bouchard relève, pour sa cinquième proposition, quelques cas de moissonnage de sites web sélectives.
Pour sa sixième proposition, Bouchard indique que «Internet crée ses propres données; c’est sa nature même» (p. 404)
«Cela démontre l’importance de comprendre la situation de l’information utilisée, non pas suivant les critères de temps, de forme, de lieu ou d’auteur auxquels nous nous référons habituellement, mais suivant leur situation dans l’entrelacement des données. Le chemin pour trouver en ligne s’avère ainsi recouvrir les mêmes dimensions que celles du chemin qui permet de trouver à partir des index des banques de données. Les deux construits nécessitent conscience et contrôle afin de mieux collecter les données pertinentes et d’en avoir une analyse plus sensée. (p. 405).»
En guise de conclusion et de septième proposition, Bouchard relate les portes closes des bibliothèques du Vatican et saute vers la surabondance du numérique.
«Comment faire ressortir de cette masse de données qui nous permettront d’enrichir la recherche en droit en la désenclavant du monopole des éditeurs traditionnels? Pour réponse, j’ai trois mots en tête: conscience, participation et méthode. Foucault, face à l’immensité de l’histoire, dit adopter l’oeil du chirurgien. Il choisit. Il choisit un point sur lequel il jette un regard clinique, il l’ouvre et le dénude, il le décortique jusqu’à l’essentiel * (p. 406) »
*Citant: Michel Foucault, Naissance de la clinique, PUF 1963, p. 123
Finalement,
Nous avons à opérer le même acte de diagnostic pour l’information en ligne. D’abord accéder à la conscience de cette information. Ensuite, participer à sa collecte afin que nos préoccupations soient prises en compte. Enfin, développer, morceau par morceau, une méthode du spécifique dans le trop grand pour nous permettre de le démystifier et de bénéficier de son essentiel (p. 406).
Bouchard offre, en annexe de son texte, une «liste non exhaustive des sites d’accès à des archives en ligne (nées numériques ou mises en ligne) (p. 407-9)»
Voici une autre lecture dans le thème des méthodes quantitatives en droit, lire le fil de ma pensée via le mot-clic «réseaux».
Une petite anecdote avant de poursuivre… cet été, j’ai visité un ami que j’ai rencontré à l’école secondaire (en 1ère pour nos amis français) et qui est maintenant prof de math à l’U Waterloo. Il m’a raconté son expérience comme membre du groupe de travail sur l’équité salariale à son institution et cette conversation m’a un peu mis la puce à l’oreille sur l’importance grandissante des analyses mathématiques et statistiques en droit. (lisez le rapport en format pdf pour y voir le rôle de l’analyse statistique dans un contexte hautement juridique de l’équité salariale) L’analyse statistique d’une masse importante de données a mené à une preuve d’une situation anormale du point de vue du droit.
De cette conversation amicale, une fois les enfants couchés, a germé l’idée de pousser mes études de la jurilinguistique au delà de la simple diffusion numérique de sources documentaires du droit et d’attaquer les méthodes quantitatives en droit – passer du corpus lui-même aux méthodes à lui appliquer. Merci Benoît de cette inspiration !
Je vous relate cette anecdote car il s’agit justement du thème de l’article dont je vous propose : le recours à l’analyse statistique dans un contexte d’équité salariale…
NIVARD, C. ET M. MÖSCHEL, «Discriminations indirectes et statistiques: entre potentialités et résistances» dans HENNETTE-VAUCHEZ, S., M. MÖSCHEL ET D. ROMAN (dir.), Ce que le genre fait au droit, coll. «À droit ouvert», Paris, Dalloz, 2013, p. 77-91
Ce texte porte directement sur le concept de «discrimination indirecte» et surtout de son introduction en Europe depuis son émergence jurisprudentielle aux USA dans les années 1971 (c.f.: Griggs c/ Duke Power Co., 401 US 424). Le lecteur désirant trouver une « recette secrète » méthodologique en mathématique ou statistique reste sur sa faim. La première partie, écrite par Carole Nivard, traite de l’utilisation de méthodes statistiques dans plusieurs causes de discrimination indirecte récentes sans en relever les teneurs mathématiques. Selon Nivard,
«La Cour de Justice a en effet tendance à renvoyer aux juges internes l’appréciation du caractère significatif des statistiques en cas de «batailles de chiffres» * entre les parties. La Cour européenne des droits de l’homme retient quant à elle les statistiques qui lui «paraissent fiables et significatives» ** après avoir procédé à un «examen critique» ***. »
* Citant: Conclusion de l’Avocat général Léger sur l’arrêt CJCE 14 décembre 1995, Inge Nolte c/ Landesversicherungsanstalt Hannover, C-317/93. Recueil I-4625, para. 53
** citant: CEDH, gr. ch., 13 novembre 2007, D.H. et autres c/ République tchèque, n. 57325/00, para 188
*** citant: Ibid. («Cela ne veux toutefois pas dire que la production des statistiques soit indispensables pour prover la discrimination indirecte»)
(p. 81)
Ensuite, Nivard explore comment les statistiques sont un «outil performant en voie de généralisation» dans la 2e section de la première partie de cet article écrit à quatre mains.
Pour sa part, Möschel poursuit la rédaction de l’article par la 2e partie traitant de la discrimination indirecte comme outil encore «contesté». Cette partie, quoi que fort intéressante sur le plan du fond juridique, ne touche pas à la forme statistique comme telle.
Son premier texte donne le ton. Pluralisme, réseaux, effectivité, la question de la réalité juridique dépasse largement le stricte cadre des lois édictées par l’état. Comme il précise dans son texte introductif :
Mais dans un univers en réseau comme celui qui prévaut désormais, la loi s’énonce de plus en plus selon des méthodes et stratégies reflétant son application dans des contextes diversifiés. Elle émane parfois de l’État, parfois d’autres acteurs.
Dans ce monde dans lequel nous avons des droits et sommes obligés de tenir compte des droits des autres, il paraît nécessaire de parcourir les tenants et aboutissants des lois, des droits et des obligations. Il est essentiel de débattre des fondements et de la structure des lois dans lesquels sont énoncés nos droits tout comme les techniques utilisées pour énoncer et mettre en oeuvre les objectifs publics.
Dans son second, Pierre explore comment Facebook est, en quelque sorte, une entité souveraine, dont le pouvoir influence les utilisateurs de manières insoupçonnées.
Ces deux textes illustrent de nouvelles conceptualisations d’un ordre (Rocher, 1988) ou système juridique (Ost et van de Kerchove). Certains pourraient croire que ces dynamiques sont propres au numériques. Certes, le numérique est un terreau fertile de systèmes juridiques privés, mélangeant le code et les contrats pour dicter des moyens d’interagir avec des documents et d’autres humains qui permettent l’émergence d’externalités positives ou négatives. Mais, la réalité est, comme toujours, plus complexe et plus subtile.
Or, comme j’ai déjà souligné ici, l’objectif de Macdonald, en traitant de la gouvernance, est de positionner l’intervention des individus en fonction de leurs actions en prenant ses distances de la vision interventionniste de l’État.
«Human beings express their agency through their acts of self-governance and through their voluntary or coerced participation in governance structures that they share with others and that channel the occasions for exercising this human legacy»
Dans certains cas, les structures sont directement ou indirectement imposées: syndicats; politiques institutionnelles; code volontaires; système électoral;plateforme numériques etc. Dans d’autres, ils « émergent » de la volonté de participants comme dans le cas évident du code source et et de la culture libre mais aussi des communautés de brevets et des communs en général. Ainsi, le concept de la gouvernance, solidement ancré dans le pluralisme juridique, invite le chercheur en droit de se questionner sur les ramifications téléologiques de ses approches herméneutiques dans les diverses sphères disciplinaires (traduction en français non-académique: de penser à ce qui se passe réellement en considérant que le droit n’est qu’un facteur qui se conjugue au social, politique, économique, philosophique, etc.).
Il est donc absolument nécessaire d’employer des cadres conceptuels flexibles intimement liés au droit public tout en portant son regard vers des éléments « autour » du droit. Certains lecteurs perspicaces pourraient prétendre que cette approche est encrée en droit privé et je dois concéder que la frontière entre le droit privé et le droit public est ténue dans le contexte de la gouvernance. Dun côté, le droit privé invite à observer les relations contractuelles entre les personne. De l’autre, le droit public vise à comprendre les dynamiques du droit posé (la Loi) et du contrôle de celui-ci par les cours. La gouvernance suppose que les sources normatives dans un environnement sont ni l’état, ni les cours mais que celles-ci sont une source normative parmi tant d’autre. Ainsi, le contrat, traditionnellement associé au droit privé, peut devenir source de droit positif dans un contexte de gouvernance. En réalité, la frontière entre le droit privé et le droit public est un point central de ma thèse et le concept de la gouvernance offre l’occasion d’effectuer le pivot de l’un vers l’autre.
Il faut donc comprendre que le monde numérique est riche en situations où la frontière entre le droit privé et le droit public s’estompe, mais il existe beaucoup plus de scénarios dans le monde analogue… c’est pourquoi j’ai toujours été ambivalent par rapport à la distinction entre le droit public et le droit privé, distinction qui nuit à l’analyse d’une réalité juridique posée et réfléchie (pour ne pas dire critique et réaliste).
Si j’ai l’air de mettre la charrue avant les boeux (boeufs pour les jeunes), hé ben, c’est que je vis dans un rodéo post-moderne !
Je suis tombé un peu par hasard sur le sujet des statistiques ou des mathématiques en droit. En fait, c’est en passant par le concept de « réseau » que j’ai débuté ce détour intellectuel. En particulier, j’ai bien aimé les théories mathématiques formelles des réseaux, surtout lorsqu’elles sont appliquées aux réseaux de citation…
D’ailleurs, le mémoire d’Éric Paré utilise propose le mot-clé « jurimétrie » – je suis habitué aux analyse bibliométriques de mon domaine et je me suis toujours demandé si la « jurimétrie » était un domaine de recherche. Une recherche sur érudit me permet de découvrir une vingtaine de textes, la plupart datant d’il y a plus 20 ans ! Il y en a 2 sur Cairn.info plus récents par contre. Il faut croire que ce concept n’est pas le bon pour entamer une découverte du domaine.
En cherchant sur le web (pour ma thèse), j’ai découvert l’école émergente du Empirical legal studies qui semble émaner des USA (voir, par exemple, la Society for empirical legal studies, son journal et ce blogue vers laquelle sa page lie). Il faut dire que je trouve le ton un peu moralisateur, surtout sur le blogue, comme si les analyses statistiques ou quantitatives sont les seules qui mènent à la vérité… Il faut lire le titre des conférences et des articles publiés pour se faire une tête rapidement.
Mais, je mélange les sujets. L’analyse par les réseaux de citations, l’analyse statistique et quantitatives ainsi que les approches informatiques et mathématiques en droit sont des choses bien distinctes, qui se recoupent éventuellement. Pour le moment, du moins, le point en commun entre ces approches serait l’outil, c’est à dire le recours à des formalisations qui puisent dans un bagage de connaissance qui n’est pas usuel en droit, celui des chiffres. (J’espère que personne ne me demandera de faire la preuve que le droit est une science de mots!)
Je crois que cet aspect est celui qui m’attire le plus. Les chiffres comme outil, sans nécessairement (encore) savoir (pleinement) dans quel cadre (théorique ou conceptuel) les appliquer. Il faut donc lire,
BOUCHARD, V., «Collecte des données et approches critiques du droit: du trop peu au trop grand» dans AZZARIA, G. (dir.), Les cadres théoriques et le droit : actes de la 2e Journée d’étude sur la méthodologie et l’épistémologie juridiques, Cowansville, Québec, Éditions Y. Blais, 2013, p. 381-406
MELOT, R. ET J. PÉLISSE, «Prendre la mesure du droit : enjeux de l’observation statistique pour la sociologie juridique», (2008) 69-70 Droit et société
NIVARD, C. ET M. MÖSCHEL, «Discriminations indirectes et statistiques: entre potentialités et résistances» dans HENNETTE-VAUCHEZ, S., M. MÖSCHEL ET D. ROMAN (dir.), Ce que le genre fait au droit, coll. «À droit ouvert», Paris, Dalloz, 2013, p. 77-91
Je vais mettre la main sur ces textes bientôt… c’est la rentrée et je suis un peu occupé avec mes tâches régulières.
Par ailleurs, je suis aussi tombé sur cette étude:
Toronto [Ont.] : University of Toronto Press, c2008 (Saint-Lazare, Quebec : Gibson Library Connections, 2010)
L’auteur constitue un échantillon de tous les jugements de la Cour suprême du Canada pour les analyser (manuellement) selon une grille d’analyse qui lui est propre. Cette grille découle de sa propre conceptualisation du droit, un mix entre Hart et Dworkin, et tente d’élucider si la cour se base sur un principe juridique ou sur une loi (l’objet de son étude est de savoir si les cours ont tendance à voler la plume du législateur).
Pour le moment, je compte poursuivre ma réflexion sur les méthodes quantitatives en droit, surtout pour mieux comprendre comment utiliser ces outils dans des contextes professionnels (comme l’e-discovery) ou intellectuels (comme l’épistémologie du droit).