Je tiens à féliciter l’équipe du CQÉMI pour le lancement de leur nouveau site Internet : https://www.cqemi.org/fr/
Plusieurs rubriques y sont disponibles, comme une section Boîte à outil. Cette section propose des ressources éducatives libres sur des thèmes importants, dont la vérification des faits et la liberté d’expression.
Le libre accès est une méthode de diffusion pour une oeuvre numérique qui implique une mise en ligne à titre gratuite, contraintes tant juridiques que technologiques. Exit les limitations des licences propriétaires ou les verrous numériques. Mais cette approche question se pose : quel sont les modèles possibles de financer une telle approche ? Quel est l’impact escompté ?
Il y a plusieurs dimensions à ces questions. En premier lieu, le libre accès est un thème récurent dans l’édition scientifique, tant pour les revues édités par les pairs que les monographies. D’ailleurs, plusieurs groupes du milieu des bibliothèques proposent des ressources à leurs membres ou à la communauté à cet effet. Au Canada, notons l’excellent partenariat Coalition Publi.ca.
En fait, qui s’intéresse à la question de l’accès libre est rapidement submergé dans une vague déferlante d’information traitant du milieu académique, scientifique ou savant. Qu’en est-il du domaine (ou industrie) de l’édition littéraire et du libre accès ?
Pour un aperçu de l’univers littéraire numérique au Québec, certaines adresses sont incontournables. Débutons avec le très pertinent Édition Mammouth Numérique, qui livre sous format blogue une veille sectorielle. Ensuite, le plus récent mais non moins ambitieux le Carnet de la Fabrique Numérique est une initiative du laboratoire ExSitu de l’Université Laval (auquel je participe accessoirement par le projet Littérature Québécoise Mobile). D’ailleurs, il est essentiel de souligner l’important répertoire Opuscules lorsqu’il et question de littérature numérique au Québec !
J’oublie certainement quelques sites et initiatives, n’hésitez pas à me les souligner dans les commentaires…
Le blogue InfoJustice.org recense la mise en ligne des résultats d’une étude comparative des exceptions au droit d’auteur dans divers pays à travers le globe :
Dans leur étude, Flynn, Palmedo et Izquierdo traitent des domaines suivants:
Open research exceptions
Restrictions of Research Uses to Quotation and Excerpts
Restrictions on Uses, Works and Users
Restrictions on Sharing
Restrictions to Private Reproduction
Restrictions to Institutional Users
Restrictions on Types of Works
Fait intéressant à noter, cette étude utilise la base se donnée en libre accès compilée par l’Organisation mondiale de la propriété intellectuelle WIPO LEX qui
donne accès à titre gracieux à des informations juridiques relatives à la propriété intellectuelle dans le monde entier. Effectuez une recherche dans la base de données WIPO Lex pour accéder à 49000 documents juridiques dans nos collections de lois, traités et jugements.
Par ailleurs, les auteurs mentionnent le travail d’une équipe qui a produit une étude similaire dans le passée, sans la nommer. Je tiens à souligner l’excellent travail de Kenneth Crews (que j’ai eu l’énorme plaisir de rencontrer lorsque je siégeais sur le « Comité sur le droit d’auteur » de l’IFLA il y a une dizaine d’années). L’étude de Dr. Crews porte sur les exceptions mondiales au profit des bibliothèques.
La culture libre désigne une hypothèse de l’univers numérique, celle de mobiliser – ou mettre à disposition dans Internet – une oeuvre sans contraintes économiques, technologiques ou juridiques. Dans le cadre de leur collaboration pour l’élaboration d’un essai sur ce thème ainsi que les enjeux juridiques de la transformation numérique, Olivier Charbonneau et Marjolaine Poirier proposent d’enregistrer certains segments de leurs réunions de travail. Les thèmes explorés gravitent autour du droit d’auteur, du droit à l’image, de la gestion des renseignements personnels et de la vie privée, du statut de l’artiste et autres cadres de gouvernance juridique du numérique. La cadence anticipée est une fois par mois.
Ressources nécessaires
Nous cherchons un accompagnement pour les efforts nécessaires pour la post-production et la diffusion, notamment la manipulation des fichiers audio enregistrés, l’élaboration d’une identité visuelle et sonore ainsi que l’hébergement sur une ou des plateforme(s) pertinentes.
Le saviez-vous, novembre est le mois « national » (sic) pour écrire un roman ? C’est sous cette bonne étoile que je fais table rase pour plonger à fond dans l’écriture de mon essai.
Il faut dire que je travaille sur le projet depuis plusieurs années (ahem), toujours déraillé par des cas de force majeure dans ma vie… comme mes obligations professionnelles, familiales et hédonistes. Mais là, tsé, j’arrête de le dire et je l’écris !
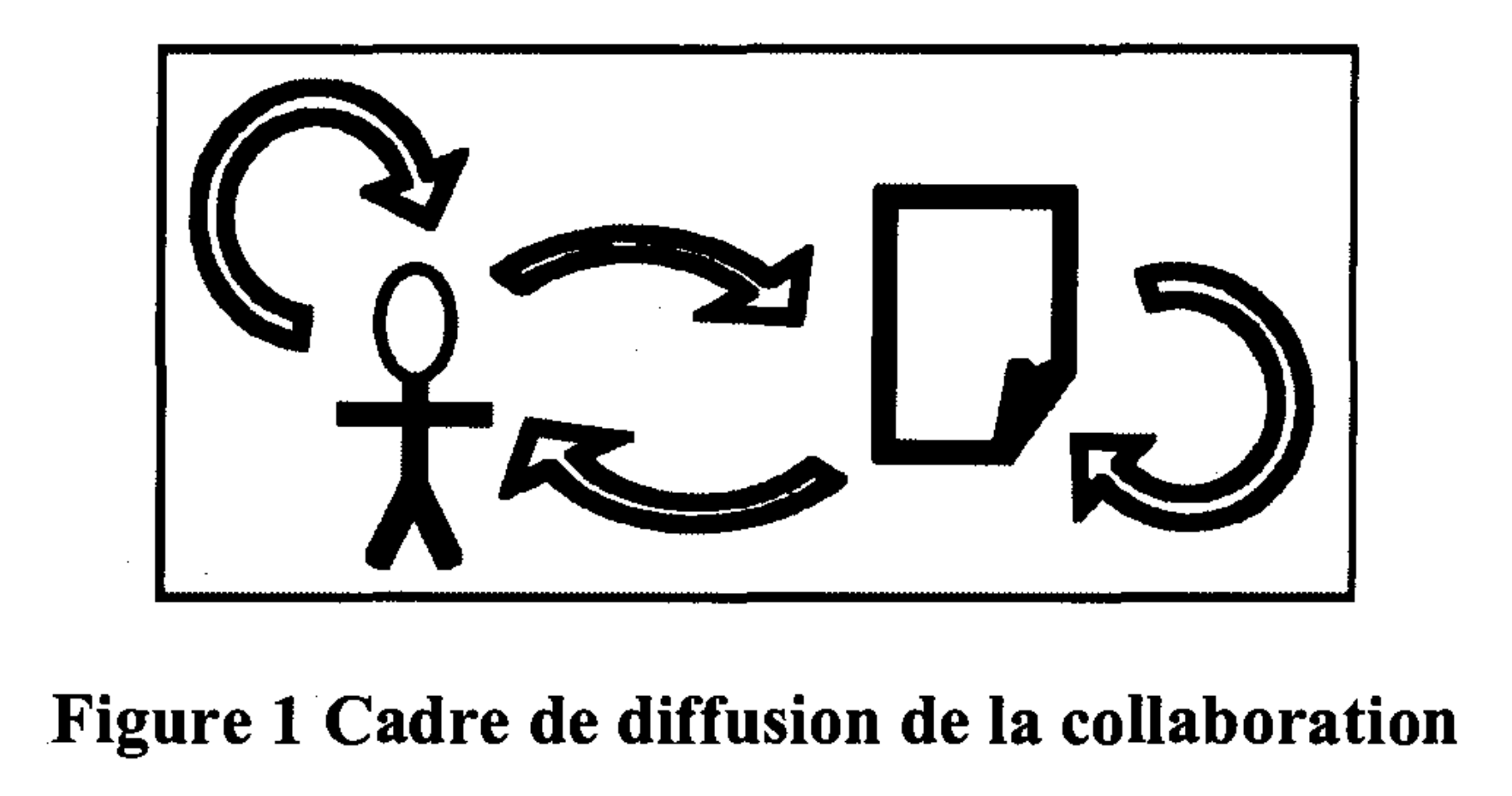
Pour arriver à l’écrire, ce fameux bouquin, il faut un plan. Je vais reprendre une très vieille idée sur laquelle je travaille depuis une décennie pour organiser mes idées. Il s’agit du «cadre de la diffusion de la collaboration» que j’ai mobilisé pour un mémoire en droit en 2008. Dans ce mémoire, j’explore comment mettre en oeuvre les concepts du contenu généré par les utilisateurs pour enrichir une archive ouverte de lois et jugements. À l’époque, j’étais membre de l’équipe LexUM, dans le temps où ce groupe était un laboratoire universitaire qui s’occupait de CanLII. Voici une synthèse visuelle de ce cadre :
Source: La jurisprudence en accès libre à l’ère du contenu généré par les usagers [Mémoire de maîtrise en droit], Université de Montréal, 2008, p. 21
J’ai poursuivi la réflexions (évidemment) lors de mes efforts doctoraux au Centre de recherche en droit public de l’Université de Montréal. Le concept que j’ai retenu pour le doc est «l’émergence» dans les systèmes socioéconomiques d’oeuvres numériques protégées par le droit d’auteur…. mais l’idée est là. Quels sont les éléments fondamentaux de tout système socioéconomique ? Quelles sont les interactions et qu’est-ce qui émerge de ce(s) système(s) ? Comme vous vous en doutez certainement, je suis cybernéticien.
Les éléments de mon modèle apparaissent déjà en 2008 : il y a des «objets» représentés par l’icône «document»; des «sujets» représenté par l’icône du personnage en bâton (vous constatez l’étendue de mon talent artistique) et quatre relations génériques représentés par des flèches. Celles-ci peuvent représenter des flux monétaires, des vecteurs juridiques (contrats), des contributions intellectuelles…
Comme je l’explique dans mon mémoire de 2008 :
[62] Ainsi, la figure humaine représente les agents d’un système, qu’ils soient les usagers d’O’Reilly ou les émetteurs et récepteurs de McMillan ou Richards. Puis, l’image d’un document représente le contenu du système, qu’il soit un espace sémantique de Hendler et Golbeck ou encore, une classe documentaire du modèle classique du Web Sémantique. Le vecteur de l’agent vers le document représente une action d’écriture, tandis que le vecteur inverse invoque la lecture (ou consommation), comme l’évoque Kiousis. Par ailleurs, la relation récursive des agents représente les échanges (Web 2.0) et autres conversations tandis que la même relation liant le contenu invoque les liens technologiques, sémantiques ou relationnels des instances des classes documentaires. [63] Notre modèle propose donc deux classes d’objets: les agents et les documents. Ces deux classes d’objets interagissent grâce à quatre relations : la lecture et l’écriture; puis les échanges et les référencements. Nous proposons ce modèle simplifié de l’interactivité afin d’évoquer la« générativity »possible d’un système reposant sur des technologies d’Internet. Il constitue notre cadre d’analyse afin d’explorer notre question de recherche.
Je tiens à souligner à mes éditeurs que le but du chercheur universitaire paresseux efficient est de faire du neuf avec de vieilles idées…
Depuis, j’ai creusé à fond ces idées dans ma thèse doctorale. Je ne vous relate pas (encore) comment mes ides ont évoluées lors de ces efforts (je dois me garder du matériel pour la suite de mon travail). Je vous livre donc l’état des choses aujourd’hui, ce sur quoi je vais plancher dans mon livre.
Donc, mon modèle, tel que je l’expose actuellement, les systèmes socioéconomiques sont (toujours) composés d’objets (ou, dans mon cas, de documents) et de sujets (ou, selon votre discipline académique, des personnes, des agents ou des acteurs sociaux). Les flèches existent toujours, mais j’en propose deux classes : les règles, un amalgame de ce que Laurence Lessig (1999, p. 88) identifie comme les normes et la loi, puis interactions, pour grouper le marché et l’architecture de Lessig (ibid). Il y a bien sûr d’autres sources intellectuelles à ces concepts… alors je saute beaucoup de citations…
L’idée est d’arriver à une approximation du modèle cybernétique standard, qui est composé de trois éléments: l’information, la rétroaction et l’entropie. Pour ma part, je propose, en ordre, les objets/sujets, les règles et les interactions. Il va sans dire que j’espère vous expliquer en détail ce modèle !
Pour le faire, je vais le mettre en relation avec lui-même. Si mon modèle était une matrice d’une dimension à quatre éléments, j’en fait le carré pour obtenir une matrice 4 x 4. Chacune des «cellules» devient un chapitre de mon livre… vous allez dire que je me complique la vie… hé bien, je vous répond que l’hiver Canadien est tout aussi rigoureux que long, alors je me réchauffe les mains en soufflant sur de chauds concepts !
Alors, la matrice résultante de mon livre s’exprime ainsi:
x
Règles
Objets
Sujets
Interactions
Règles
Objets
Sujets
Interactions
Il ne suffit que de remplir chaque chaque case avec un thème pour chaque chapitre. Je ne suis pas certain que cette matrice sera le plan final de mon livre. Ceci dit, l’exercice me permet de places mes idées et de travailler sur la relation entre celles-ci.
Voici la matrice avec quelques bribes d’idées pour une matrice de la culture libre :
x
Règles
Objets
Sujets
Interactions
Règles
Interdiction
Exclusion
Liberté Mise à disposition
Plateformes
Objets
Corpus
Données
Valeur
Algorithme
Sujets
Contextes
Transactions
Espace public
Consentement
Interactions
Certification
Métadonnées
Autorité
Gouvernance
Les intitulés présenté dans la première colonne sont des méthodes, appliquées sur les intitulés indiqués sur la première ligne. Les cellules du tableau se lit ainsi, par exemple, pour chaque élément suivant
(4,1) les règles appliquées aux interactions donnent des plateformes
(2,3), les sujets appliqués aux objets donnent des transactions
(1,4) les interactions appliqués aux règles donnent la certification
et ansi de suite
Enfin, c’est un peu fou tout ça mais c’est comme ça que mon cerveau fonctionne ! En réalité, cette approche est purement humaniste car elle ne présuppose pas que je puisse ordonner chacun de ces éléments selon une relation de dépendance. Dans les sciences sociales ou pures, chaque discipline offre (impose!) un lot de relations entre des variables qui sont acceptées comme pertinentes par l’état de la science. Les humanistes n’ont pas ce luxe : il faut tout mettre en relation car notre discipline est trop complexe pour réellement offrir un cadre conceptuel cartonné d’avance. C’est pourquoi j’offre cette approche conceptuelle en matrice, où les éléments sont multipliés ensemble. C’est ma manière d’être exhaustif dans le contexte complexe des sciences humaines.
Pour dire que mes collègues des sciences sociales et pures ont la vie facile…
Possession du droit d’auteur et oeuvres exécutées dans le cadre d’un emploi, voir respectivement l’alinéa 1 et 3 de l’article 13 de la Loi sur le droit d’auteur. Source: Loi sur le droit d’auteur, LRC 1985, c C-42, art 13, https://canlii.ca/t/ckj9#art13, consulté le 2021-11-10
Ressources éducatives libres (REL), voir l’exemple de la FabriqueREL.org.
Je me souviens encore de cette paisible journée de février. Une neige cotonneuse saupoudrait mollement Montréal tandis que je lisais mes fils RSS. C’est à ce moment que j’ai appris que Google avait ajusté, le 18 janvier 2009, certains éléments de son algorithme de tri des résultats de recherche de sites web. C’est aussi à ce moment que, selon moi, la société occidentale a basculé à l’ère post-moderne.
À l’époque, l’ingénieur Matt Cutts de Google nuançait la situation comme un ajustement mineur, nommé en l’honneur du membre de son équipe qui a mené l’initiative – le «Vince change» (le changement de Vince). Voir cette vidéo à ce effet :
Il faut dire qu’à l’époque, l’ajustement eut un impact significatif sur les efforts de lissage du référencement (ou, pour nos cousins de France: «search engine optimisation») et fit disparaître beaucoup de petits commerçants des premiers résultats, au profit des sites des grandes marques de commerce. C’est d’ailleurs ce qui demeure aujourd’hui de cette petite modification dans les sources que j’ai consulté… j’ai tenté en vain d’obtenir plus de détails sur le «Vince Change» de 2009 et c’est tout ce que j’ai trouvé. (Oui, j’ai même exploré des articles scientifiques et de la presse professionnelle de l’époque via une banque de donnée spécialisée de ma bibliothèque universitaire)
J’ai le vif souvenir d’avoir appris que depuis le 18 janvier 2009, l’algorithme de tri du moteur de recherche de Google répond aux requêtes avec des résultats optimisés pour l’individu lançant la recherche. Dans la vidéo, l’ingénieur Cutts mentionne que l’algorithme retiens toujours la confiance, l’autorité et la réputation («trust, authority, reputation») comme critères de base pour le tri des résultats. Mais qu’en est-il de cette idée que Google offre des résultats distincts en vertu de la personne effectuant la requête? Il s’agit, selon certains, de la source des chambres d’écho du Web. J’ai également inclus cette perspective dans mon enseignement des habitudes de recherche à mes étudiants.
Donc, j’ai souvenir que le 18 janvier 2009 fut le moment où Google a cessé de retourner les mêmes résultats pour tout le monde avec la même requête. Nous quittons le monde positiviste / naturaliste où une structure (ou ontologie) globale gouvernait le système. Nous entrons un cadre relativiste, pluraliste, personnel. Si le fait et le savoir gouvernent un système soit naturaliste ou positiviste, l’opinion et la croyance s’imbrique dans le relationnel. Ce qui est «vrai» découle donc de son approche épistémique (c’est-à-dire, notre façon de penser dicte notre de comprendre le monde). Cet argument mérite d’être déconstruit, voire amélioré – j’y reviendrai… dans l’intérim, je vous propose cette courte vidéo de mon collègue (et très chic type) Vivek Venkatesh, qui utilise judicieusement la distinction entre la pensée positiviste/naturaliste et relationnelle pour expliquer le racisme systémique sur le site du quotidien Montréalais Le Devoir.
Pourquoi est-ce que je vous parle de tout ceci? Simplement à cause du nouveau livre de Eric Schmidt (ancien grand patron de Google et Alphabet) avec Henry A Kissinger (!) et Daniel Huttenlocher dont le titre est assez évocateur : The age of AI and our human future (l’âge de l’intelligence artificielle et notre futur humain).
Il me semble que la recherche web via Google est un exemple probant de l’impact d’un algorithme apprenant (je déteste intelligence artificielle) sur la société. Il s’agit d’un outil essentiel qui est probablement mal utilisé par la vaste majorité… Simplement car chaque recherche effectuée fait partie d’une longue conversation avec une entité apprenante plutôt qu’un acte distinct. Il faut traiter Google comme la machine qu’elle est, celle qui décide ce que nous pouvons découvrir sur le web en vertu de ce qu’elle sait de nous.
Je vous laisse avec ma vidéo où j’explique, justement, comment entretenir cette conversation à long terme avec votre Google (en anglais, la langue de mon milieu de travail)
J’ai l’énorme plaisir d’annoncer que j’ai repris le contrôle de mon site, après un acte de piraterie qui a affecté le service OpenUM de l’Université de Montréal. Ainsi, plus de 150 carnets de recherche ont été affectés, depuis le 24 septembre. Tous les écrits depuis le 21 mai 2021 ont disparus mais, fort heureusement, la fabuleuse équipe technologique de l’Université de Montréal et du service OpenUM ont travaillé fort pour relancer nos activités.
Sur un autre ordre d’idées, j’ai aussi « perdu » les données de mon ordinateur personnel, à cause d’une mise à jour système bâclée. Celle-ci n’est pas reliée à l’attaque informatique sur mon blogue sauf que pour quelques temps, j’ai eu l’impression de fureter dans le vide…
Dans ces circonstances, je vous offre un tonitruant : « HELLO WORLD ! »
Voici la captation de la vidéo de la présentation sur les fiducies de données en culture, dans le cadre du projet de recherche Littérature Québécoise Mobile (LQM) avec Anne-Sophie Hulin: