Ces pages furent créées dans le passé et je ne veux ni les diffuser, ni les effacer.
Conférence CultureLibre.ca
Le 15 septembre 2017 à 13h30, aura lieu ma soutenance de ma thèse doctorale
Olivier Charbonneau 2017-08-23
La date de ma soutenance doctorale est le 15 septembre 2017 à 13h30 au local A-3464 (Faculté de droit, Université de Montréal). Son titre est:
Émergence de normes dans les systèmes économiques et sociaux d’oeuvres numériques protégées par droit d’auteur
Mon jury est composé des professeurs suivants:
- Professeur Vincent Gautrais, Université de Montréal, président-rapporteur
- Professeur Pierre Trudel, Université de Montréal, directeur de recherche
- Professeure Pascale Chapdelaine, Université de Windsor, examinatrice externe
- Professeure Marie Demoulin, Université de Montréal, membre du jury
- Professeur Nicolas Vermeys, Université de Montréal, membre du jury
Voici le sommaire:
Pris dans le maelström des révolutions technologiques, de la mondialisation et des revendications de divers groupes sociaux, le droit d’auteur édicte tant bien que mal les dispositions qui règlementent les
systèmes économiques et sociaux où transitent les oeuvres protégées. Notre thèse a comme objectif principal de repérer les normes qui émergent des pratiques de développement des collections numériques par les bibliothèques. Un but accessoire consiste à théoriser sur la « frontière » qui sépare le recours aux licences et le recours aux exceptions du droit d’auteur, tel que l’utilisation équitable. Nous articulons notre cadre
conceptuel et analytique autour de la perspective des utilisateurs d’oeuvres numériques protégées par le droit d’auteur.
La première partie de notre thèse traite de notre objet d’étude : l’oeuvre numérique protégée par droit d’auteur. Nous employons l’analyse économique du droit pour articuler deux axiomes intrinsèquement liés à la nature de l’oeuvre. D’une part, l’oeuvre oscille naturellement entre la nature économique d’un droit de propriété, un bien privé, et la conception utilitariste qui se comprend mieux par les biens publics. Nous nommons cette réalité le paradoxe quantique de l’oeuvre. De l’autre, l’oeuvre change d’un état à l’autre grâce à une multitude d’institutions ou moyens édictés par le droit d’auteur, par exemple : les concessions, les limitations et les exceptions. Si nous ordonnons ces dispositions sur une droite formée par le niveau de risque engendré par chaque utilisation, nous obtenons ce que nous nommons le continuum du consentement, où le risque est inversement proportionnel au consentement du titulaire.
La seconde partie de cette thèse considère les sujets de droit : les agents des systèmes sociaux qui utilisent des oeuvres numériques protégées par le droit d’auteur. Nous étoffons notre cadre conceptuel autour des théories sociologiques du droit, afin d’articuler comment les systèmes sociaux peuvent générer des normes. Pour ce faire, nous puisons dans les nouvelles théories du droit en réseau, de la gestion des risques et de l’internormativité contractuelle. Nous proposons un cadre d’analyse socioéconomique, où se juxtaposent les objets de droit et les sujets de droit. Nous opérationnalisons ce cadre en combinant les éléments de notremodèle dans une matrice oeuvres-utilisateurs où chaque cellule constitue un cadre juridique précis.
La troisième et dernière partie de notre thèse concerne le cadre juridique qui émerge d’un système social particulier, celui des bibliothèques universitaires agissant en réseau grâce à des consortiums d’acquisition.
Nous employons les développements récents en mécanisation et informatisation des rapports contractuels pour analyser le contenu normatif d’une classe de licences d’accès à des oeuvres numériques protégées par droit d’auteur. Les métadonnées représentent le contenu normatif desdites licences et les données d’instances offrent l’occasion d’effectuer des analyses statistiques pour confirmer l’émergence de normes.
Nous concluons que les activités qui mènent à la formation d’ententes d’accès au sein des bibliothèques universitaires au Québec permettent l’émergence de normes dans les systèmes socioéconomiques des oeuvres numériques protégées par le droit d’auteur. Par ailleurs, nous confirmons que ces ententes portent sur des utilisations visées par plusieurs régimes juridiques édictant des exceptions aux droits d’auteur. Nous croyons qu’il s’agit d’un exemple où les institutions emploient des moyens économiques et sociaux pour dépasser le simple cadre juridique édicté par le droit d’auteur et qui vise l’établissement d’un ordre basé sur un contrat social lié à la mission des bibliothèques.
Je diffuserai ma thèse par Internet suite à ma soutenance.
Document numérique Lettres
Avoir la mesure des mots (lecture de Hermeutica de Rockwell & Sinclair, MIT Press 2016)
Olivier Charbonneau 2017-08-23
Suite à mon exploration de l’outil Voyant-tools pour l’analyse textuelle, la Société canadienne des humanités numériques a décerné son prix annuel à Stéfan Sinclair, Professeur à McGill et directeur du centre de recherche sur les humanités numériques, et À Geoffrey Rockwell, professeur de philosophie à l’University of Alberta, pour leur outil Voyant-tools ainsi que leur livre décrivant leur parcours intellectuel intitulé: Hermeneutica : computer-assisted interpretation in the humanities. Je me suis empressé d’emprunter et de lire leur monographie afin de mieux comprendre l’outil qu’ils ont créé…
Les auteurs offrent une réflexion sur leur démarche intellectuelle dans le recours à des outils technologiques pour l’analyse textuelle sourtout dans le domaine des études littéraires. Voici quelques passages qui ont retenu mon attention. Par ailleurs, je cite deux autres livres à la toute fin de ce billet – ils concernent eux aussi le domaine (surtout le livre de Holsti, qui ne figure pas dans la bibliographie de Rockwell & Sinclair mais qui traite d’un sujet très proche).
Je crois que le travail de Rockwell & Sinclair dans Hermeneutica permet de mieux comprendre comment le domaine des études littéraires s’est approprié l’outil informatique. J’espère m’en inspirer largement dans l’analyse empirique et informatique du droit… Selon les auteurs,
This book, to be clear, is not about what we can learn from corpus linguistics or computational linguistics. Rather, it is rooted in the traditions of computer-assisted text analysis in literary studies and other interpretive disciplines and the more hermeneutical ends of philosophy and history. It is about that tradition as much as it is about what you can do with hermeneutical things. Insofar as the tradition of literary text analysis has evolved in parallel with computational linguistics without building on it, we feel justified in leaving that for another project.
The use of interpretive tools in the social sciences is also outside the purview of this book. There is a tradition of qualitative techniques and tools for analyzing interviews or other texts of interest to social scientists. This is similar to literary text analysis, in that it uses computers to interpret texts, but the goals and methods are different. Atlas.ti, NVivo, and similar tools help social scientists with content analysis for social scientific aims. They are not meant to help understand the texts themselves so much as to help understand the phenomena of which texts such as interview transcripts are evidence. Again, as with linguistic analysis, we could learn a lot from such
(p. 19)
tools and traditions of research practice, but they are beyond the scope of this book. (p. 20)
En citant les travaux de Smith, Rockwell & Sinclair tentent de développer une approche théorique basée sur une approche itérative de l’interrogation d’un corpus (p.86-7). Smith a précédé Rockwell & Sinclair de quelques décennies mais fut confronté à la même problématique qu’eux: comment développer une approche méthodologique face à la montagne de données, statistiques, mesures, et autres calculs possibles sur un corpos précis.
In his article “Computer Criticism” Smith completes the move from imagery, as it is manifest in computer visualizations of various kinds, to a critical theory that opens the way for computational methods. What makes this hermeneutical circle even more interesting is that the aesthetic theory voiced by Stephen Dedalus nicely captures the encounter with the visualization. Dedalus has developed an idea from the medieval philosopher Thomas Aquinas. The encounter with art, Dedalus argues, passes through three phases:
1. Integritas: First, the aesthetic image (visual, audible, or literate) is encountered in its wholeness as set off from the rest of the visible universe.
[…]
2. Consonantia: Then one apprehends the harmony of the whole and the parts.
(p. 88)
[…]
3. Claritas: And finally one sees the work in its particular radiance as a unique thing, bounded from the rest but with harmonious parts. […]
These three phases or this aesthetic encounter make a pattern that we can use for the interpretive encounter. The sequence might be something like the following steps, the first two having been outlined in chapter 2 and the third covering how results are returned to you (the subject of this chapter).
Demarcation First, one has to identify and demarcate the text (or corpus) one is going to interpret. In that choice one is defining the boundary of a work or collection from the rest for the purposes of interpretation. Pragmatically this takes the form of choosing a digital text and preparing it for study.
Analysis Second, one breaks the whole into parts and studies how those parts contribute to the form of the whole. Smith, in “Computer Criticism,” suggests that this is where the computer can assist in interpretation. Stephen Dedalus summarizes this as analyzing “according to its form.” 18 The computer can automate the analysis of a text into smaller units (tokens). Even individual words can be identified and be used as the unit for analysis.
Synthesis Third, there is a synthesis of the analytical insights and interpretive moves into a new form that attempts to explain the particular art
of the work being studied. That is the synthesis into visualizations and then into an essay; a new work that attempts to clarify the interpreted work. These syntheses are hermeneutica.
When we return later to theorize computer-assisted interpretation, we will look more closely at Smith’s structuralist critical theory, the weakest part of his triptych of illustrative essay, theory, and tools.
(références pour ce passage)
Smith , J. B. Image and imagery in Joyce’s Portrait: A computer-assisted analysis . In Directions in Literary Criticism: Contemporary Approaches to Literature, ed. S. Weintraub and P. Young . University Park : Pennsylvania State University Press , 1973 .
Smith , J. B. 1978 . Computer criticism. Style 12 ( 4 ): 326 – 356 .
Smith , J. B. 1984 . A new environment for literary analysis. Perspectives in Computing 4 ( 2/3 ): 20 – 31 .
Smith , J. B. 1985 . Arras User’s Manual. TextLab Report TR85-036, Department of Computer Science, University of North Carolina, Chapel Hill.
(Important: Stephen Dedalus est l’aterego littéraire de James Joyce, l’auteur qu’analyse Smith.)
Les auteurs considèrent que l’accessibilité accrue à des corpus numériques et aux outils pour les analyser introduisent des mutations dans leur discupline:
Big data has been trumpeted as the next big thing made possible by the explosion of digital data about us, to which we contribute. As we write this, big data probably is at the high point in the Hype Cycle —there are inflated expectations as to how it will transform business, government, and the academy, and soon there are likely to be more sober evaluations. Drawing on Mayer-Schönberger and Cukier’s book Big Data, we characterize how
big data changes methods as follows:
From samples to comprehensive data In the humanities and the social sciences, traditionally we either focus on works that are considered distinctive or sample larger phenomena. Big data draws on relatively complete datasets, often created for entirely different purposes, and uses them for new research. These datasets are comprehensive in a way that sampling isn’t, and in a way that can change the types of questions asked and can change people’s confidence in the answers.
(p. 125)
From purposeful data to messy and repurposed data Traditionally, the data used in research are carefully gathered and curated for that research. With big data, we repurpose messy data from other sources that weren’t structured for research and we aggregate data from multiple sources. This raises ethical issues when people’s information is used for purposes they didn’t consent to; it also means that we can extract novel insights from old data, which is why preservation of data is important.
From causation to correlation Big data typically can’t be used to prove causal links between phenomena the way experiments can. Instead, big data is used to show correlations. Big data is being pitched as an opportunity to reuse data to explore for new insights in the form of correlations. There are even techniques that can comb through datasets to identify all the statistically significant correlations that could be of research interest.
What Does This Mean for the Humanities?
What does this mean for the humanities in general and the Digital Humanities in particular? Well, there are obvious privacy issues, ethical issues, and governance issues that call for attention. The liberal arts are supposed to prepare free ( liber) people for citizenship and participation in democratic community. Big data is now one way citizens are managed both by industry and by government. 25 The liberal arts clearly have a role in studying and teaching about big data. To get a conversation of the phenomenon going, the researchers danah boyd and Kate Crawford (2012) offer six provocative statements:
1. Big Data changes the definition of knowledge.
2. Claims to objectivity and accuracy are misleading.
3. Bigger data are not always better data.
4. Taken out of context, Big Data loses its meaning.
5. Just because it is accessible does not make it ethical.
6. Limited access to Big Data creates new digital divides.
Following boyd and Crawford, one way to think about big data is to look at the pragmatics of how working with large amounts of data changes knowledge. A particularly Digital Humanities way to do this is to think through experimenting with the analysis of large datasets. “Thinking through” is an approach of understanding a phenomenon (thinking about it) through the practices of making, experimenting, and fiddling. It is one of the ways the Digital Humanities can contribute to the larger dialogue of the humanities through what Tito Orlandi and later Willard McCarty called
(p. 126)
modeling. We create models of systems and learn through the iterative making and reflecting on the models—especially when they fail, as they usually do. The false positives that our hermeneutica throw up tell us about the limitations of our models and hence about the limitations of the theories of knowledge on which they are based.
Ainsi, (p. 128-130)
What Can We Do with Big Data Analytics?
At this point, let us take a quick tour through some of the opportunities and risks for Big Data in the Digital Humanities.
Filtering and subsetting We begin with a basic operation comparable to what intelligence services do with Information in Motion: filtering big data to get useful subsets that can then be studied by other, possibly traditional techniques (e.g., reading). The Cornell Web Lab, which alas was closed in 2011, was working with the Internet Archive to build a system that would enable social scientists (and humanists) to extract subsets from the archive. The dearth of resources that allow for navigation between large databases of content (among them the Gutenberg Project of digital texts) to specialized environments for reading and analysis should be noted here.
Enrichment “Enrichment” is a general term for adding value. In the context of big data, researchers are developing ways to enrich large corpora automatically using the knowledge in big data. In “What Do You Do with a Million Books?” (the 2006 article that first prompted many of us to begin thinking about what big data meant in the humanities), Greg Crane wrote eloquently about what we now can do to enrich big data to make it more useful. Crane has made the further point that simply providing translation enrichment could provide us with a platform for a dialogue among civilizations.
Sequence alignment Sequence alignment can be adapted from bioinformatics for the purpose of following passages through time. This is the research equivalent to what plagiarism detectors do with students’ papers. They look at sequences of text to see whether similar passages can be found in other texts, contemporary or not. Horton, Olsen, and Roe (2010) described work they had done with the ARTFL textbase to track how passages in an influential twentieth-century history by Paul Hazard had been cribbed from a seventeenth-century text. The point is not that Hazard was a lazy note taker, but that one can follow the expression of ideas across writers when one has them in digital form.
Diachronic analysis Diachronic analysis is using data sets to study change over time. Although the use of large diachronic databases dates back to
(p. 129)
the Trésor de la langue française (TLF) and the Thesaurus Linguae Grecae (TLG) projects, diachronic analysis got a lot of attention after Google made its Ngram Viewer available and after Jean-Baptiste Michel and colleagues published their paper “On Quantitative Analysis of Culture Using Millions of Digitized Books” (2010). There are dangers to using Ngrams (or phrases of words) to follow ideas when the very words have changed in meaning, orthography, and use over time, but the Ngram Viewer is nonetheless a powerful tool for testing change in language over time (and its search-and-graph approach makes it accessible to a broad public).
Classification and clustering Classification and clustering comprise a large family of techniques that go under various names and can be used to explore data. Classification and clustering techniques typically workon large collections of documents and allow us to automatically classify the genre of a work or to ask the computer to generate clusters according to specific features and see if they correspond to existing classifications. A related technique, Topic Modeling, identifies clusters of words that could be the major “topics” (distinctive terms that co-occur) of a large collection. An example was given in the previous chapter, where we used correspondence analysis to identify clusters of key words and years in the Humanist archives.
Social network analysis Social network analysis (SNA) involves identifying people and other entities and then analyzing how they are linked in the data. It is popular both in the intelligence community and in the social sciences. SNA techniques can graph a network of people to show how they are connected and to what degree they are connected. In the social sciences, the data underlying a network typically are gathered manually. One might for example interview members of a community in order to understand the network of relationships in that community. The resulting data about the links between people can be visualized or queried by computer. These techniques can be applied in the humanities when one wants to track the connections between characters in a work (Moretti 2013), or the connections between correspondents in a collection of letters or places mentioned in a play. Just as an ethnographer might formally document relationships between people, a historian might be interested in determining who lived in Athens when Socrates was martyred and how those people were connected. Large collectionsof church records, letters, and other documents now allow us to study social networks of the past. Thanks to a new family of techniques that can recognize the names of people, organizations, or places in a text, it is
(p. 130)
now possible to extract named entity data automatically from large text collections, as the Voyant tool called RezoViz does.
Self-tracking Self-tracking is the application of big data to your life. You can gather big data about yourself. Personal surveillance technologies allow you to gather lots of data about where you go and who you correspond with, and to then analyze it. The idea is to “know thyself” better and in more detail (or perhaps just to remind you to exercise more). Though results of self-tracking may not seem to be big data relative to the datasets gathered by the NSA, they can accumulate to the point where one must use mining tools to make sense of it. A fascinating early project in life tracking was Lifestream, started in the 1990s as a project at Yale by Eric Freeman and David Gelernter, which introduced interesting interface ideas about how information could be organized according to the chronological stream of life. 31 Gordon Bell has a project at Microsoft called MyLifeBits that has led to a commercially available camera, the Vicon Revue; you hang it around your neck, and it shoots pictures all day to frame bits of your life. 32 Recently Stephen Wolfram, of Mathematica fame, has posted an interesting blog essay on what he has learned by analyzing data he gathered about his activities—an ongoing process that, he argues, contributes to his self-awareness. 33 Many different tools are now available to enable the rest of us to gather, analyze, and share data about ourselves—especially data on our physical fitness data. (Among those tools are the fitbit, the Nike+ line, 34 and now the Apple Watch.)
Les auteurs (p. 128) proposent les lectures suivantes pour aller plus loin:
Jockers , M. L. 2013 . Macroanalysis: Digital Methods and Literary History. Urbana : University of Illinois Press .
Moretti , F. 2007 . Graphs, Maps, Trees: Abstract Models for Literary History. London : Verso .
Moretti , F. 2013 a. The end of the beginning: A reply to Christopher Prendergast . In Moretti, Distant Reading. London : Verso ,
Moretti , F. 2013 b. Network theory, plot analysis . In Moretti, Distant Reading . London : Verso .
L’analyse de données massives et textuelles amène certains écueils.
The problem is that when you analyze a lot of data you get a lot of false hits or false positives. The messier the data, the more false hits you get. The subtler the questions asked of the data, the more nuanced and even misleading the answers are likely to be. When you use Google to search for someone with a common name, such as John Smith, with big data you can get overwhelmingly big and disappointingly irrelevant results—result sets that are too big for you to go through to find the answer, and therefore not useful. (p. 131)
Par ailleurs,
A second problem with analysis of big data is the dependence on correlation. It doesn’t tell you about what causes what; it tells you only what correlates with what (Mayer-Schönberger and Cukier 2013, chapter 4). With enough data one can get spurious correlations, as there is always something that has the same statistical profile as the phenomenon you are studying. This is the machine equivalent to apophenia, the human tendency to see patterns everywhere, which is akin to what Umberto Eco explores in Interpretation and Overinterpretation (1992).
The dependence on correlations has interesting implications. In 2008, Chris Anderson, the editor in chief of Wired, announced “the end of theory,” by which he meant the end of scientific theory. He argued that with lots of data we don’t have to start with a theory and then gather data to test it. We can now use statistical techniques to explore data for correlations with which to explain the world without theory. Proving causation through the scientific method is now being surpassed by exploratory practices that make big science seem a lot more like the humanities. It remains to be seen how big data might change theorizing in the humanities. Could lots of exploratory results overwhelm or trivialize theory? What new theories are needed for working with lots of data?
A related problem is “model drift” or “concept drift,” which is what happens when the data change but the analytical model doesn’t. […] The fact that people’s use of language changes over time is a major problem for humanities projects that use historical data. People don’t use certain words today the same way they used those words in the past, and that’s a problem for text (p. 133) mining that depends on words. If you are modeling concepts over time, the change in language has to be accounted for in the model—an accounting that raises a variety of interpretive questions. Does a phrase that you are tracking have the same meaning it had in the past, or has its meaning evolved?
(p. 132-3)
Eco , U. 1992 . Interpretation and Overinterpretation. Cambridge University Press .
Mayer-Schönberger , V. , and K. Cukier . 2013 . Big Data: A Revolution That Will Transform How We Live, Work, and Think. New York : Houghton Mifflin Harcourt
Ainsi, les auteur concluent (p. 133-4)
Similar questions about cost effectiveness should be asked, and are being asked, about text analysis and mining in the humanities. Does text mining of large corpora provide real insight? There are two types of questions that we need to keep always in mind in analysis, especially in regard to largescale analysis:
• Are the methods and their application sound, and can they be tested by alternative methods (or at the very least, are we sufficiently circumspect about the data and methodologies)? In large-scale text analysis or “distant reading,” it is easy to misapply an algorithm and generate a false result. It is also easy to overinterpret results. Since at the scale of big data one can’t confirm a result by re-reading the sources, it is important to
confirm results in various ways. There is a temptation to use the size of the data to legitimize not testing results by reading, but there are always way to test results. Jockers (2013) shows us how one should always be (p. 134) sceptical of results and develop ways of testing results even if one can’t
test them by reading.
• Are the results worth the effort? Obviously, people who engage in text analysis and in data mining believe that the results are interesting enough to justify continuing, but at an individual level and at a disciplinary level we need to ask whether these methods are worth the resources. Computational
analysis is expensive not so much in terms of computing (of which there is an ample supply thanks to high-performance computing initiatives) as in terms of the human effort required to do it well. Is computational analysis worth the training, the negotiating of resources, and the programming it requires? Individuals at Voyant workshops ask this question in various ways. Also important are the disciplinary discussions taking place in departments and faculties that are deciding whether to hire in the Digital Humanities and whether to run courses in analytics. Hermeneutica can help those departments and faculties to “kick the tires” of text analysis as a pragmatic way of testing analytical methods in general.
Les auteurs offrent un exemple de leur cru des écueils de l’analyse de données massives et textuelles.
We have our own story about too many results—a story that points out another form of false positive in which the falsity is more that of a false friend. In May of 2010 we ran a workshop on
High-Performance Computing (HPC) and the Digital Humanities at the University of Alberta. We brought together a number of teams with HPC support so they could prototype HPC applications in the humanities. One team adapted Patrick Juola’s
idea for a Conjecturator (Juola and Bernola 2009) so that it could run on one of the University of Alberta’s HPC machines. The Conjecturator is a data-mining tool that can generate a nearly infinite number of conjectures about a big dataset and then test them to see if they are statistically interesting.
The opposite of a “finding” tool that shows only what you ask for, it generates statistically tested assertions about your dataset that could be
studied more closely. The assertions take this form:
Feature A appears more/less often
in the group of texts B than in group C
that are distinguished by structural feature D
Citant:
Juola, Patrick, Bernola, Ashley (2009). ‘Conjecture Generation in the Digital Humanities’. Proc. DH-2009. 2009
Les auteurs indiquent que cette approche, lorsqu’appliquée au corpus de tous les livres publiés en 1850 génère plus de 87000 affirmations positives!! Ils pointent vers la fin de la théorisation scientifique classique (p. 132 – citant Chris Anderson qui, en 2008, a annoncé la fin de la théorisation scientifique). Donc, quoi faire avec 87000 théories?
• Many of the results are trivial. They may be statistically valid, but many nonetheless are uninteresting to humans.
• Many of the results are related. You might find that there is a set of related assertions about shirts over many decades.
• The results are hard to interpret in the dialogical sense. You may find a really interesting assertion but have no way to test it, follow it, or unpack it. The Conjecturator is not usefully connected to a full-textanalysis
environment in which one could explore an interesting assertion. As always, the trajectory from the very atomistic level (the narrow and specific assertions) to larger, more significant aspects is unmarked and hazardous, though not without potential rewards. (p. 135)
Vers une théorie modèle
Les auteurs (p. 152) indiquent que les travaux de Busa, avec l’aide de Tasman qui travaille pour IBM sont un pount de départ pertinent pour l’émergence des humanités numériques en études littéraires:
These are some of the first theoretical reflections on text analysis by a developer. Though they aren’t the earliest such reflections, Busa’s ideas and his project are generally considered major initial influences in DH. 10 His essay positioned concordances as tools for uncovering and recovering the meanings of words in their original contexts. Busa is in a philological tradition that prizes the recovery of the historical context of language. To interpret (p. 153) a text, one must reconstitute the conceptual system of its author and its author’s context independent of the text.
A concordance refocuses the philological reader on the language. It structures a different type of reading: one in which a reader can see how a term is used across a writer’s works, rather than following the narrative or logic of an individual work. A concordance breaks the train of thought; it is an instrument for seeing the text differently. One looks across texts rather then through a text. The instrument, by its very nature, rearranges the text by showing and hiding (showing occurrences of key words and their context grouped together and hiding the text in its original sequence) so as to support a different reading.
Busa , R. 1980 . The annals of humanities computing: The Index Thomisticus. Computers and the Humanities 14 ( 2 ): 83 – 90 .
Tasman , P. 1957 Literary data processing. IBM Journal of Research and Development 1 ( 3 ): 249 – 256 .
J’aime particulièrement cette idée selon laquelle: One looks across texts rather then through a text. The instrument, by its very nature, rearranges the text by showing and hiding (p. 153)
En poursuivant leur survol des textes fondateurs, les auteurs proposent ceci sur Smith 1978 (précité), à la page 156:
Smith reminds us that the term “computer criticism” is potentially misleading, insofar as the human interpreter, not the computer, does the criticism. Smith insists that “the computer is simply amplifying the critic’s powers of perception and recall in concert with conventional perspectives.” [Smith 1978, p327] It would be more accurate to call his theory one of “computer-assisted criticism,” in a tradition of thinking of the computer as extending hermeneutical abilities. According to Smith, “the full implications of regarding the literary work as a sequence of signs, as a material object, that is “waiting” to be characterized by external models or systems, have to be realized.” [ibid] The core of Smith’s theory, however, comes from an insight into the particular materiality of the electronic text. As we pointed out in chapter 2, computers see a text not as a book with a binding, pages, ink marks, and coffee stains, but as a sequence of characters. The electronic text is a formalization of an idea about what the text is, and that formalization translates one material form into another. It is just another edition in a history of productions and consumption of editions.
The computer can help us to identify, compare, and study a document’s formal structures or those fitted to it. The process of text analysis, with its computational tools and techniques, is as much about understanding our interpretations of a text, by formalizing them, as it is about the text itself. Smith is not proposing that the computer can uncover some secret structure in the text so much as that it can help us understand the theoretical
structures we want to fit to the text.
An example of a structure interpreted onto the text is a theme. Here is what Smith wrote about mapping themes onto Joyce’s prose by searching
for collections of related words:
The concept of distribution is a diachronic, “horizontal” concept of structure that characterizes patterns along one of the vertical strata described earlier; a different concept of form or structure is the collection of synchronic relations among a number of such distributions. Synchronic patterns of interrelation are, essentially, patterns of co-occurrence. [Citant Smith 1978, p. 339]
In “Computer Criticism” (1978) and “A New Environment for Literary Analysis” (1984) Smith talks about following a “fire” theme; in “Image and Imagery in Joyce’s Portrait” (1973) he gives an example of how he studies such thematic structures. Smith describes a mental model of the text as vertical layers or columns. Imagine all the words in the text as the leftmost base column, with one word per line. Then imagine a column that marks which words belong to the fire theme. That layer could be plotted horizontally in a distribution graph. If one has a number of these structural columns, then one can also study the co-occurrence of themes across rows. Do certain themes appear in the same paragraphs, for example?
Smith anticipated text-mining research methods that are only now coming into use. He describes using Principal Component Analysis (PCA) to identify themes co-occurring synchronically, then cites examples of state diagrams and CGAMS that can present 3D models of the themes in a text. The visualizations are graphical presentations of structural models can be used to explore themes and their relations. [Smith 1978 p.343]
In the late 1970s, Smith was trying to find visual models that could be woven into research practices. He called some of his methods Computer Generated Analogues of Mental Structure (CGAMS), drawing our attention to how he was trying to think through the cognitive practices of literary study that might be enabled by the computer. Like Perry’s model railroad, CGAMS provide a model theory that has explanatory and scalable power. The visualizations model a text in a way that can be explored, and they act as examples that a computer-assisted critic can use to model his or her own interpretations.
Les auteurs poursuivent en précisant que Smith a lié ses efforts à l’analyse littéraire en passant par les travaux de Rolland Barthes et surtout, le structuralisme (Barthes , R. 1972 . The Structuralist Activity: Critical Essays. Evanston : Northwestern University Press), ainsi:
structuralism should not be seen as a discovering of some inherent or essential structure, but as an activity of composition (p. 157)
[…] citation de Barthes 1972, pp. 214-5 & Référence ibid, p. 216
Ainsi:
That the computer forces one to formally define any text and any method makes this structuralist understanding of interpretation even more attractive as a way of understanding computer-assisted criticism.
The computer can help us with the activities of dissection and composition when what we want to study has been represented electronically. 27 The computer can analyze the text and then synthesize new simulacra for interpretation that are invested with the meanings that we (both the “we” of the developers of the tools and the “we” of users issuing queries) bring. (p. 158)
[À la note 27, les auteurs citent Rockwell , G. 2001 . The visual concordance: The design of Eye-ConTact. Text Technology 10 ( 1 ): 73 – 86. Rockwell utilise l’analogie du monstre pour l’analyse littéraire: comme Frankenstein qui est composé de divers morceaux ]
Les auteurs (p. 162) proposent que deux classes de théories sont pertinentes dans les humanités numériques: les instruments et les modèles.
À propos des instruments:
Certain instruments are theories of interpretation. An instrument implements a theory of interpreting the phenomenon it was designed to bring into view. It orients the user toward certain features in the phenomenon and away from others. The designer made the choice of what to show and what to hide. The user may tune it, but the instrument is, in effect, saying “This is important; that is not.” As Margaret Masterman wrote in “The Intellect’s New Eye” (1962), “the potential capacity of the digital computer to process nonnumerical data in novel ways—that capacity the surface of which has hardly been scratched as yet—is so great as to make of it the telescope of the mind.” (p. 162)
Citant
Masterman , M. 1962 . The intellect’s new eye . In Freeing the Mind: Articles and Letters from the Times Literary Supplement during March–June, 1962 . London : Times .
Quant aux modèles,
Thus, the things of the Digital Humanities are all models that are formalized interpretations of cultural objects. Even a process as apparently trivial as digitizing involves choices that foreground things that we formerly took for granted, forcing us to theorize at least to the point of being able to formalize. In order to be able to know what we are digitizing and how to do so, we need to develop a hermeneutical theory of things.
Through the process of digitizing we end up with three types of models: a theoretical model of the problem or cultural phenomenon; a working model of an instance of the phenomenon based on the first; and a model of the process whereby we will get the second, which may be semi-automated in code. The first is a model that is closer to what we mean by a hermeneutical theory. The second is the software, such as the e-text, that instantiates the theory to a greater or a lesser extent. The third is a model of the processing of the second, and that is what can be captured in practices and in tools (whether digitizing tools, analytical tools, or presentational tools). P. 163)
| Call Number |
AZ 186 R63 2016 |
|
| Title |
Hermeneutica : computer-assisted interpretation in the humanities / Geoffrey Rockwell and Stéfan Sinclair. |
|
| Description |
viii, 246 pages : illustrations ; 24 cm. |
| Bibliography |
Includes bibliographical references (pages [227]-239) and index. |
| Contents |
Introduction: Correcting method — The measured words : how computers analyze texts — From the concordance to ubiquitous analytics — First interlude: The swallow flies swiftly through : an analysis of Humanist — There’s a toy in my essay : problems with the rhetoric of text analysis — Second interlude: Now analyze that! : comparing the discourse on race — False positives : opportunities and dangers in big text analysis — Third interlude: Name games : analyzing game studies — A model theory : thinking-through hermeneutical things — Final interlude: The artifice of dialogue : thinking-through scepticism in Hume’s dialogues — Conclusion: Agile hermeneutics and the conversation of the humanities. |
| Scope and content |
« With increasing interest being shown in participatory research models, whether it be Wikipedia, World of Warcraft, participatory writing (like Montfort et al’s 10 Print or Laurel et al’s Design Research) or the more traditional communal research cultures of the arts collective or engineering lab, the Humanities is increasingly relying on computational tools to do the ‘heavy lifting’ necessary to process all of this information. Hermeneuti.ca, as its name implies, is about hermeneutical things–the computing tools of research that are usually hidden–how to use them, and how they are interpretative objects to be understood. Hermeneuti.ca is both a book and also a web site (http://hermeneuti.ca) that shows the interactive text analysis tools woven into the book. Essentially, Hermeneuti.ca is both a text about computer-assisted methods and a collection of analytical tools called Voyant (http://voyant-tools.org) that instantiate the authors ideas. While there is a definitely an emphasis on classic Digital Humanities work (corpus analysis, information retrieval, etc.), there is also a focus on the development of software as part of a project of knowledge that encompasses the idea of software as an active part of knowledge production that brings this book into the Software Studies series »–Provided by publisher. |
| Subject Heading |
Humanities — Research. |
| Digital humanities. |
| Humanities — Methodology. |
| Alternate Author |
Sinclair, Stéfan, author. |
| ISBN |
9780262034357 hardcover ; alkaline paper |
| 0262034352 hardcover ; alkaline paper |
|
| Call Number |
QA 76.76 H94B37 2013 |
|
| Title |
Memory machines : the evolution of hypertext / Belinda Barnet ; with a foreword by Stuart Moulthrop. |
|
| Description |
xxvi, 166 pages ; 24 cm. |
| Series |
Anthem scholarship in the digital age. |
|
Anthem scholarship in the digital age. |
| Bibliography |
Includes bibliographical references and index. |
| Contents |
Foreword: To Mandelbrot in Heaven / Stuart Moulthrop — Technical Evolution — Memex as an Image of Potentiality — Augmenting the Intellect : NLS — The Magical Place of Literary Memory : Xanadu — Seeing and Making Connections : HES and FRESS — Machine-Enhanced (Re)minding : Development of Storyspace. |
| Subject Heading |
Hypertext systems — History. |
| ISBN |
9780857280602 (hardcover : alkaline paper) |
|
0857280600 (hardcover : alkaline paper) |
|
| Title |
Content analysis for the social sciences and humanities / Ole R. Holsti. — |
|
| Publisher |
Reading, Mass. : Addison-Wesley Pub. Co., [1969] |
|
Amérique du Nord Propriété intellectuelle Réforme
L’été, c’est fait pour… consulter
Olivier Charbonneau 2017-06-29
Pour les québécoi.se.s d’un certain âge (dont je fais partie), l’émission pour enfant Passe-Partout est une source intarissable de références culturelles. Tous les poussinots et poussinettes savent que l’été c’est fait pour jouer, sauf ceux et celles des gouvernements du Canada et du Québec, ainsi que les juges du pays, qui décident d’utiliser la belle saison pour nous faire réfléchir et travailler.
Cet été, nous avons droit à deux consultations publiques d’intérêt, l’une du gouvernement fédéral pour l’ALÉNA, et l’autre du gouvernement du Québec sur sa nouvelle politique culturelle. De plus, nos juges ne chôment pas cet été, en plus de la récente décision Google Inc. c. Equustek Solutions Inc. (qui traite d’une injonction imposant à Google de retirer des liens vers du matériel numérique contrefait sur ses serveurs à l’extérieur du Canada), on peut s’attendre à certaines décisions intéressantes (dont celle impliquant l’Université de York et Access Copryright, la société de gestion collective du droit d’auteur au Canada anglais).
Débutons avec la consultation du gouvernement fédéral sur l’accord de livre-échange avec les USA – l’ALÉNA (je traiterai de la consultation pour la nouvelle politique culturelle québécoise dans un autre billet).
Avant tout, l’institut de recherche en politique publique (Canada) diffuse un dossier intitulé « Repenser la politique canadienne sur le droit d’auteur » dans sa revue Options Politiques.
Repenser la politique canadienne sur le droit d’auteur
Ce dossier tombe à pic car le gouvernement fédéral consulte les citoyens du pays sur les enjeux découlant du traité de libre échange avec les États-Unis, l’ALÉNA. Le lien entre un accord de libre-échange et la propriété intellectuelle peut sembler ténu, mais la réalité est tout autre. Le droit d’auteur, les brevets et les autres domaines de la propriété intellectuelle édictent des droits de propriété sur du savoir ou des idées. Les États-Unis ont recours aux accords bilatéraux pour lisser les législations d’autres pays en sa faveur. Ironiquement, la première mouture de l’ALÉNA, entrée en vigueur en 1993, édicte un chapitre sur la PI mais fut négociée avant qu’Internet et le numérique ne bouscule les industries culturelles et du savoir. Compte tenu des récriminations du gouvernement Trump contre nos pratiques commerciales, nous auront droit à une négociation difficile.
En fait, plus du trois-quart de nos exportations vont chez nos voisins du sud. Certaines industries, dont le bois d’oeuvre (surtout la matière ligneuse récoltée sur les terres de la couronne que les USA associent à des subventions masquées) et la gestion de l’offre en agriculture (domaines laitiers et céréaliers par exemple) embêtent les américains. Par ailleurs, le Canada figure sur la liste noire des USA concernant la propriété intellectuelle depuis des années. D’ailleurs, l’infatigable blogueur Michael Geist, professeur en droit des TI à l’Université d’Ottawa, propose une série de billets pour décrypter la position américaine sur les questions numériques susceptibles de tomber dans la collimateur des négociations.
En plus des questions de propriété intellectuelle, il est également question de « l’exception culturelle » qui est très chère à nos fournisseurs de contenu, les écrivain.ne.s, les musicien.ne.s et les act.rices.eurs… tout l’appareillage de support à la création et à la diffusion pourrait tomber dans le broyeur américain par le biais de cette négociation…
Ainsi, je suis en train de préparer mes réponses aux questions lancées par le gouvernement fédéral pour préparer les négociations de l’ALÉNA. Je les partagent avec vous pour susciter la réflexion et vous inviter à également contribuer à ce processus démocratique dans la négociation souveraine entre un géant commercial et son voisin parfois complaisant:
*À votre avis, quelles devraient être les priorités du Gouvernement du Canada dans cette renégociation de l’ALÉNA (ex. enjeux commerciaux, pratiques commerciales)?
Le Canada doit bâtir et maintenir une rhétorique commerciale qui dépasse le simple cadre économique. En ce sens, il est essentiel d’incorporer des modèles ou conceptualisations novateurs basés sur une approche critique et réflexive plus large. À cette fin, il faut introduire de nouvelles théories pour mieux saisir le rôle du droit et de l’économie dans l’organisation de l’activité humaine.
La doxa économique contemporaine se divise en deux pôles intellectuels. D’un côté, l’approche économique dite néoclassique favorise l’analyse transactionnelle des marchés de biens généralement homogènes. De l’autre, l’approche néolibérale élève les marchés comme structure institutionnelle incontournable, voire hégémonique, dans l’organisation sociale et industrielle. Ces deux approches intellectuelles sont pertinentes surtout lors de l’analyse des interactions compétitives de corporations à l’intérieur d’un marché donné (ou de marchés complémentaires). Elles dominent la rhétorique commerciale de nos voisins.
Par contre, ces théories échouent à la fois sur le plan téléologique et exogène. Rapidement, une analyse téléologique vise à observer la finalité, l’effet d’une politique publique sur la société. L’analyse des facteurs exogènes, quant à elle, observe les facteurs externes à un système social pour comprendre l’interaction entre le système observé et son environnement extérieur. Ainsi, un argument purement économique, qui n’incorpore pas une analyse des asymétries de pouvoir, des risques, des défaillances de marchés ou des externalités, ne mènera pas à des politiques publiques pertinentes, pérennes et évolutives. Outre l’analyse néoinstitutionnelle en économie, les théories pluralistes du droit, les théories des communs de Ostrom ainsi que la sociologie cybernétique offrent des pistes de solutions aux écueils de la pensée traditionnelle en économie.
Ainsi, le Canada doit analyser ses positions commerciales en fonction de ces nouvelles approches théoriques et intellectuelles afin de mieux contextualiser comment les récriminations ou revendications des États-Unis peuvent nous nuire.
*Y a-t-il des éléments de l’ALÉNA qui fonctionnent bien et qui devraient être préservés ou améliorés?
La libre circulation des individus, surtout dans le cadre de leur emploi, est un élément à maintenir et améliorer, dont les visas de travail pour certains secteurs clé dont les technologies de l’information, la santé et les bibliothèques.
*Êtes-vous au courant de pratiques commerciales, de lois ou de règlements aux États-Unis ou au Mexique qui nuisent ou qui pourraient nuire à l’accès au marché pour les produits et services canadiens?
Oui. Dans le domaine culturel, les plateformes de diffusion (Google de Alphabet, Amazon, Facebook, Netflix, iTunes de Apple) ne répondent pas aux besoin des canadiens. Leur opération et leur organisation est basée sur des algorithmes qui n’incorporent pas nos préoccupations sur la découvrabilité de notre culture ainsi que l’équité et la diversité des voix dans l’expression de celle-ci.
*Y a-t-il des enjeux que vous aimeriez ajouter dans l’ALÉNA, ou alors des enjeux dont vous ameriez voir la couverture étendue pour refléter l’évolution du commerce depuis l’entrée en vigueur de l’ALÉNA ?
Oui. Internet et les questions des technologies de l’information ont des répercussions juridiques, économiques et sociales. Il est important de protéger nos pratiques, surtout pour maintenir les droits des utilisateurs dans le domaine de la propriété intellectuelle comme les exceptions au droit d’auteur, la liberté d’expression, le financement de la culture (« exception culturelle »), la découvrabilité de notre contenu dans l’univers numérique et le rôle nuisible des plateformes et de leurs algorithmes dans les politiques publiques canadiennes.
De plus, le financement étatique dans l’industrie de la culture et des communication est essentielle à la viabilité des marchés nationaux. Les politiques de nos voisins ne portent pas attention aux externalités négatives et aux défaillances de marchés qui découlent d’une analyse purement économique. La culture est bien plus qu’un marché et nous devons bâtir une rhétorique commerciale en lien avec des théories progressives en économie, en droit et en sociologie.
Autre commentaire:
Les théories favorisant les analyses téléologiques et exogènes sont utiles pour tous les domaines économiques, comme le bois d’oeuvre ou la gestion de l’offre en agriculture. En fait, les ressources naturelles, l’agriculture et l’information, la culture et le savoir sont des domaines analogues de par la nature publique de ces biens dans la théorie économique. Ce que je propose comme approche intellectuelle pour le domaine du patrimoine et de la culture s’applique également pour tous les domaines d’intérêt stratégique pour le Canada.
Accès libre au droit Test
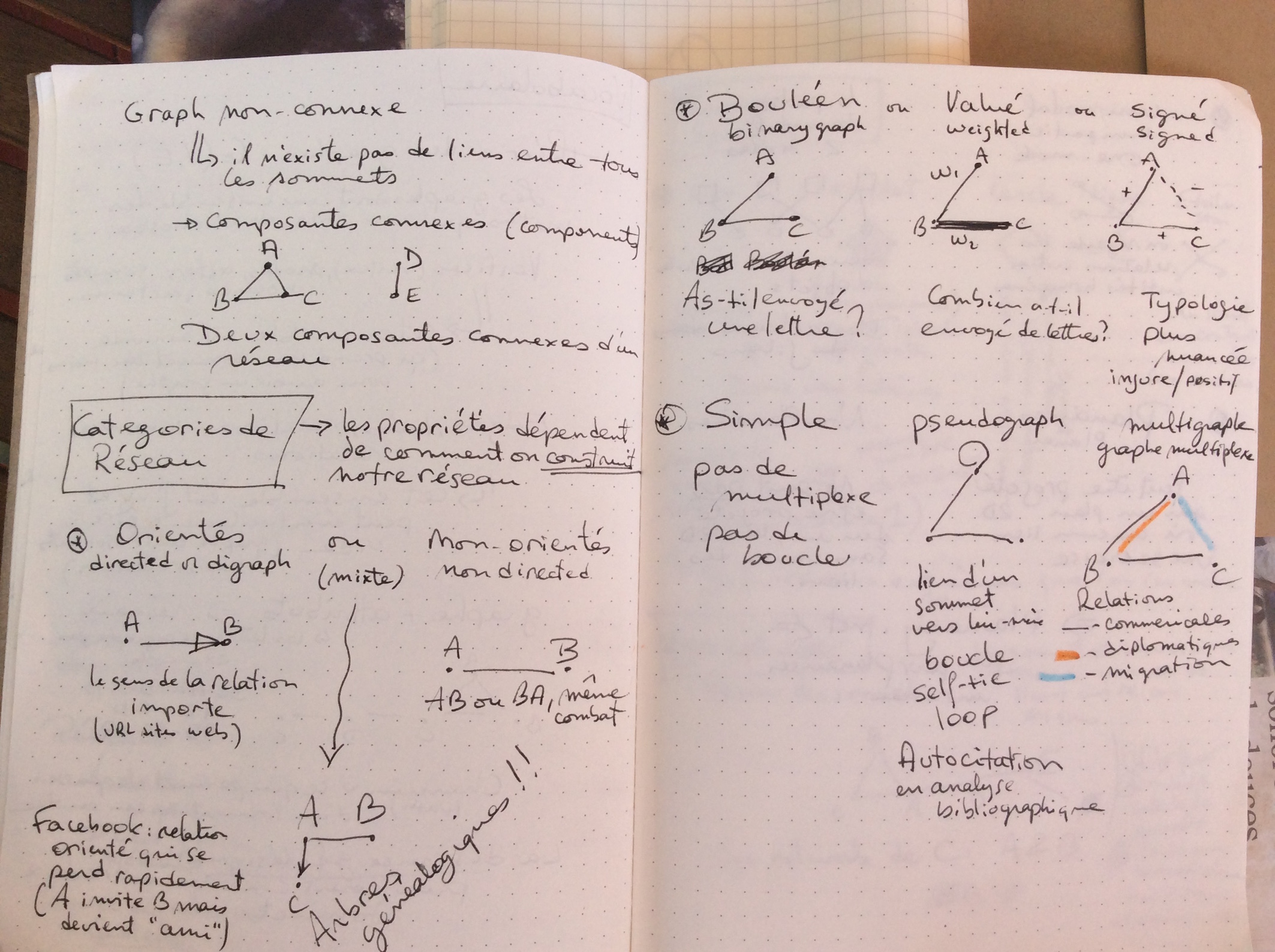
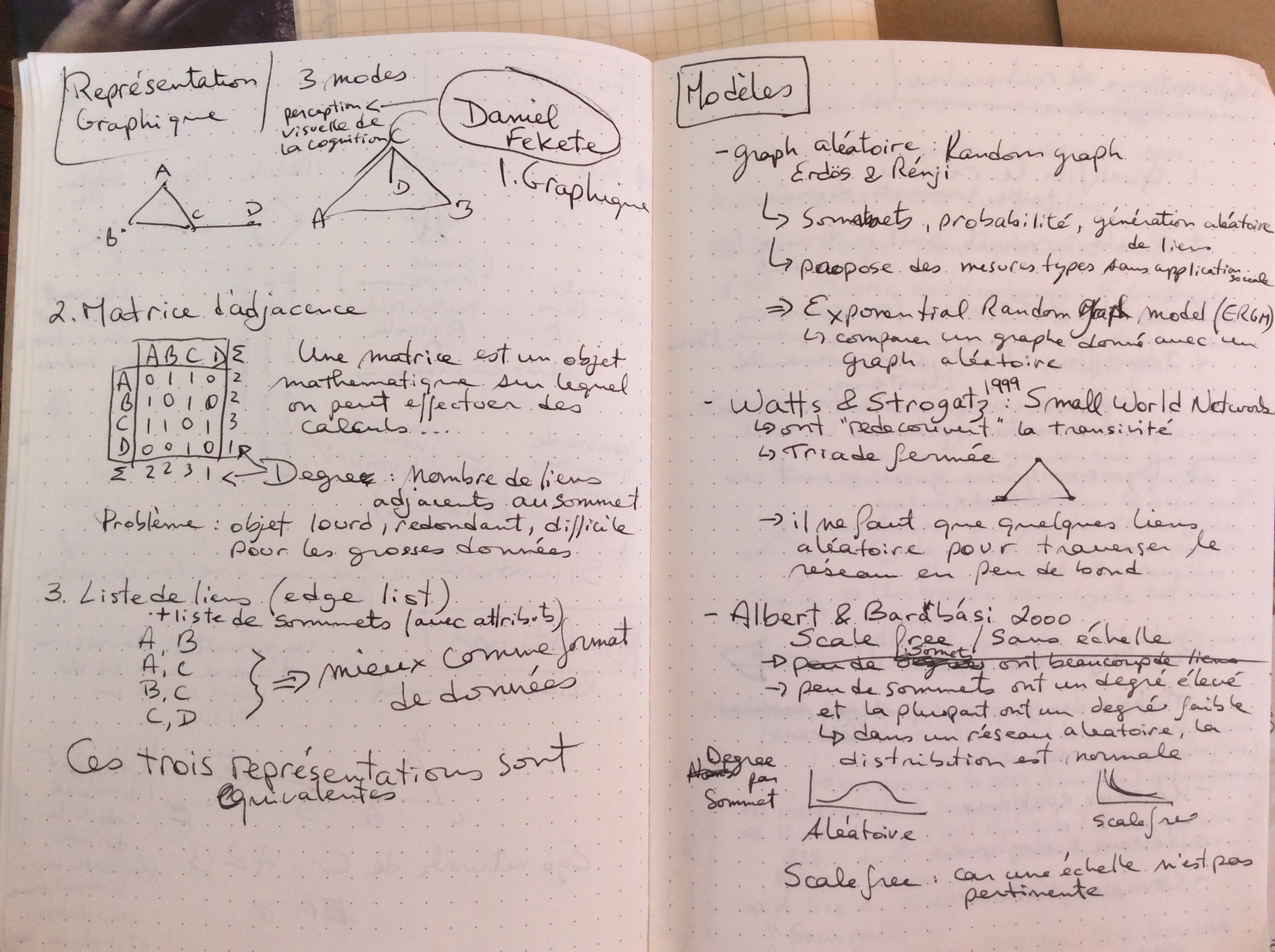
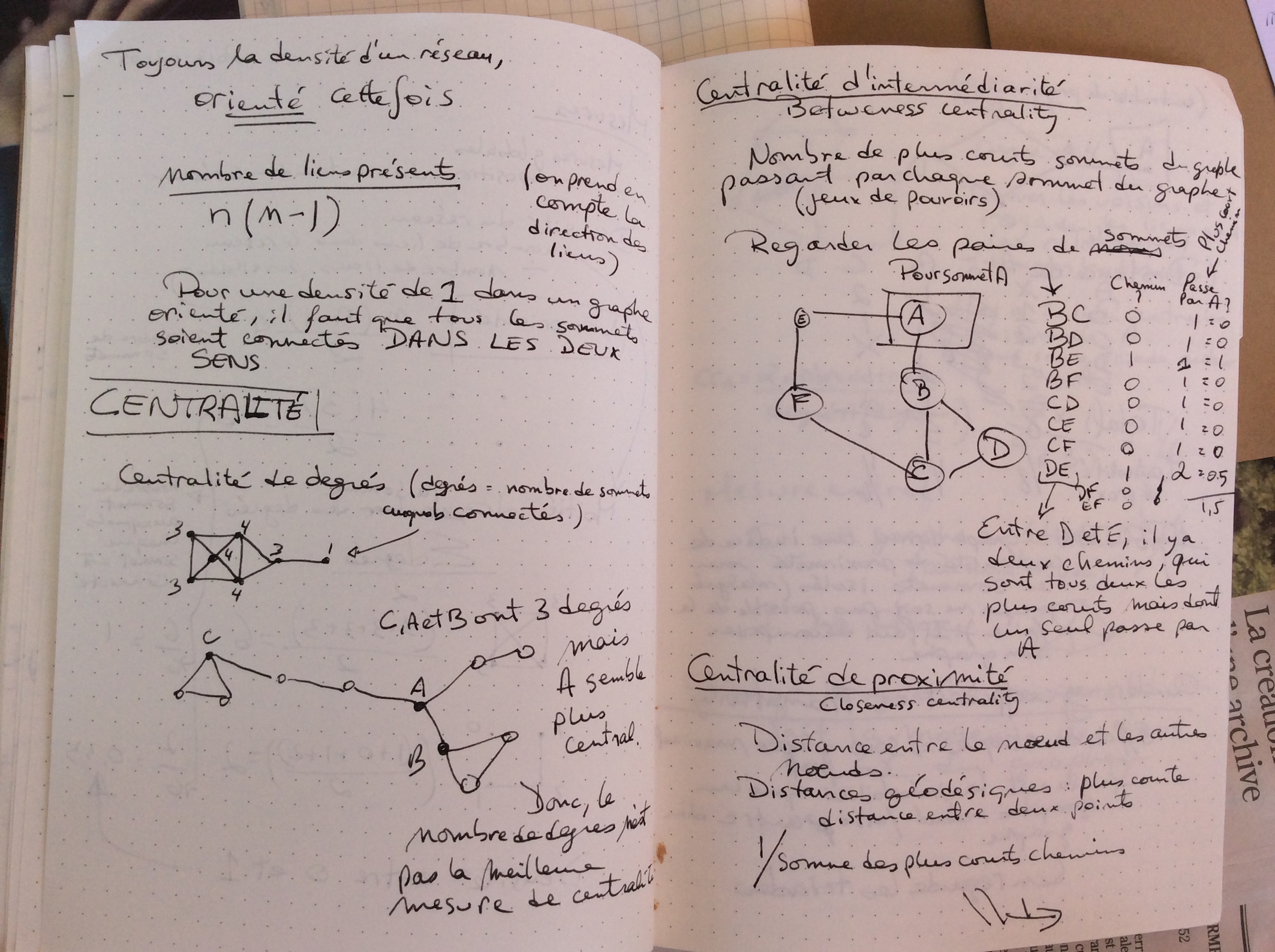
Regard sur les données – analyse en réseau
Olivier Charbonneau 2017-06-26
Pour préparer ma participation prochaine à l’École d’été du GDR Analyse de réseaux en sciences humaines et sociales à l’Université de nice la semaine prochaine, voici quelques détails sur mes recherches, surtout les sources de données que je compte explorer. D’ailleurs, je vous invite à lire la suite de billets sur les réseaux…
Dans un premier temps, je m’intéresse aux données du droit, surtout les données bibliographiques et les citations de documents juridiques, que je divise en deux catégories.
Primo, il y a les références explicites entres les sources premières du droit, soit les lois et les jugements. Toutes ces données sont disponibles dans CanLII, l’archive ouverte en droit Canadien, par le truchement d’un API (je vais devoir coder un accès aux données moi-même pour obtenir ce dont j’ai besoin). Pour les jugements, il est disponible de voir quels jugements citent d’autres jugements. Pour les Lois, il est possible de savoir combien de fois un article est utilisé ou cité en cour. Bien sûr, il faut bâtir son code soi-même mais les données sont à priori disponibles pour les chercheurs.
Secundo, il y a les données bibliographiques « autour » du droit, comme les dictionnaires juridiques ou la doctrine (les écrits à propos du droit). Dans les deux cas, il est plus complexe de récupérer ces données mais la tâche ne semble pas impossible pour qui sait solliciter des organisations publiques pour des documents diffusés librement par internet (fait à noter, la communauté juridique canadienne a tôt fait d’épouser le libre accès par Internet pour les documents juridiques).
Dans un second temps, je m’intéresse aux données culturelles en libre accès pour effectuer des analyses en réseau. Par exemple, le portail de données ouvertes du Québec offre une vitrine sur les jeux disponibles. Je m’intéresse surtout aux données issues du milieu des bibliothèques.
L’intérêt pour moi de l’école d’été sur l’initiation à l’analyse en réseau consiste à pouvoir théoriser des approches méthodologiques pour ces deux groupements de données puis d’apprendre à travailler grâce à l’expertise des formateurs. Donc, théoriser et travailler.
=======================
PS. Voici quelques éléments que j’ai inclus dans mon dossier de candidature pour l’école d’été:
Projet de recherche et corpus
Mon projet actuel vise à analyser les réseaux de citation de sources premières du droit (lois et jugements) et de la doctrine (ouvrages de référence, monographies) diffusées librement via Internet par divers organismes publics afin de déterminer de nouvelles théorisations et approches méthodologies afin de comprendre les règles juridiques d’un pays. Le Canada est un laboratoire juridique fascinent pour deux raisons : 1) à cause de la cohabitation de la common law et du droit civil dans un contexte bilingue; et 2) grâce à la diffusion libre de notre droit par des archives ouvertes nationales telles que CanLII.org, des bibliothèques des Barreaux telles que le site d’eDoctrine du Centre d’accès à l’information juridique (la bibliothèque du Barreau du Québec) ou des projets universitaires comme les dictionnaires du Centre Paul Crépeau de la Faculté de droit de l’Université McGill (pour ne citer qu’elles : voir aussi le projet jurisource.ca qui vise indexer toutes les sources libres du droit canadien).
Méthode prévue
De toute évidence, l’intérêt principal de toutes ces sources en libre accès consiste à effectuer des analyses des citations entre sources premières du droit et de la doctrine. Souvent, il s’agit de simples hyperliens. Par contre, il est possible de travailler avec ces intervenants pour élaborer des stratégies d’enrichissement des bases existantes, grâce, notamment, aux données ouvertes liées (par exemple, je collabore informellement avec les dirigeants de CanLII.org et je suis membre du comité technique du projet des dictionnaires du Centre Crépeau). Serait-il possible de théoriser de nouvelles manières de comprendre le droit par l’analyse des réseaux de citations? Est-il possible d’arrimer l’investissement stratégique dans la diffusion libre du droit avec les approches de l’analyse en réseau? Que peut-on apprendre des approches visuelles et statistiques des réseaux de citation dans et autour du droit?
Intérêt pour l’analyse en réseau
Le droit se diffuse de plus en plus via Internet et il est essentiel pour que les juristes et les chercheur.e.s en sciences humaines et sociales réfléchissent à employer l’analyse en réseau afin de s’approprier la complexité du droit et rattraper les prestataires commerciaux (algorithmes de pertinence, intelligences artificielle, etc.) quant aux méthodes informatiques de leur discipline. J’espère que votre École d’été m’offrira les outils nécessaires afin de poursuivre mes efforts en ce sens.
Document numérique Droit Test
Cadres juridiques des documents numériques
Olivier Charbonneau 2017-06-22
Je suis retombé par hazard sur le livre de Mélanie de Dulong de Rosnay intitulé Les Golems du numérique : Droit d’auteur et Lex Electronica et je me suis mis à chercher une liste exhaustive des cadres juridiques applicables aux documents numériques et j’ai déterré deux acétates d’une présentation que j’ai fait dans le cadre du cours de Réjean Savard en 2010.
Dans la première, Gowers (2006 , p. 13) propose une ontologie simplifiée du champ d’application de la propriété intellectuelle à la connaissance.

Dans la seconde, je tente de nommer tous les cadres juridiques applicables aux sciences de l’information (mon intention en 2010).

Maintenant, je tente de recenser tous les cadres juridiques applicables aud documents numériques. En ce qui concerne le droit, ce que le document contient déterminera le cadres juridiques applicable. Ainsi:
1. Si le document contient de la connaissance, il se peut que le droit de la propriété intellectuelle s’applique (c.f. : l’image de Gowers ci-haut) selon le cas: droit d’auteur, brevet, marque de commerce, design industriel, etc. Il se peut que les lois sur le statut d’artiste, les bibliothèques/archives nationales, le développement de l’industrie du livre, la liberté d’expression, la diffamation et le secret industriel soient à considerer.
2. Si le document provient d’une instance gouvernementale ou d’une organisation détenant des informations publiques (certaines données financières d’entreprises cotées en bourse; débiteurs de l’État; récipiendaires d’une subvention…), les lois sur l’accès aux documents publics s’appliquent ainsi que la loi sur le cadre juridique des TI selon le cas.
3. Si le document inclut des éléments concernant des personnes physiques, les lois sur la gestion des renseignements personnels, la vie privée, l’anonymat ou le droit à l’image s’appliquent.
4. Les marchés (analyse économique du droit), plateformes (lex électronica: la gouvernance par la technologie) ou organisations où les documents numériques sont créés ou échangés, ainsi que les contrats qui y sont négociés (e.g.: les moyens privés de bâtir un cadre juridique), peuvent favoriser l’émergence d’un système juridique privé ou non-régalien : réglementation, compétition, standards, gouvernance, normes, subventions de l’État, contrats types, métadonnes juridiques.
Accès libre au droit
Comment ne pas lire un jugement : Voyant-Tools et l’analyse de contenu
Olivier Charbonneau 2017-06-09
Le droit est une discipline textuelle. Jugements, lois, doctrine: la création et la consommation de textes est un talent que le juriste doit maîtriser ou périr.
Il y a une valeur à la lenteur dans un domaine aussi complexe et primordial pour la société, c’est pourquoi il faut concevoir de nouveaux outils technologiques pour le droit avec prudence.
Par exemple, l’intelligence artificielle est à nos portes. Le gouvernement du Québec se targue de ce secteur florissant à Montréal. Google offre des outils DIY pour bidouiller ses propres applications avec son intelligence artificielle (en plus de ses propres réussites). Sans oublier Watson d’IBM – qui a bien compris qu’en donnant son outil, nous allons lui nourrir nos textes pour enrichir son corpus, donc son « intelligence » probable. En réalité, une large proportion du code informatique nécessaire pour créer des algorithmes apprenants est aisément disponible dans Internet.
Et c’est bien là le nerf de la guerre – non pas le code, qui se partage et circule entre universitaires, corporations et bidouilleurs – mais bien la configuration algorithmique ainsi que l’accès aux corpus. Ces deux éléments dictent si une solution en intelligence artificielle sera destructrice pour la société.
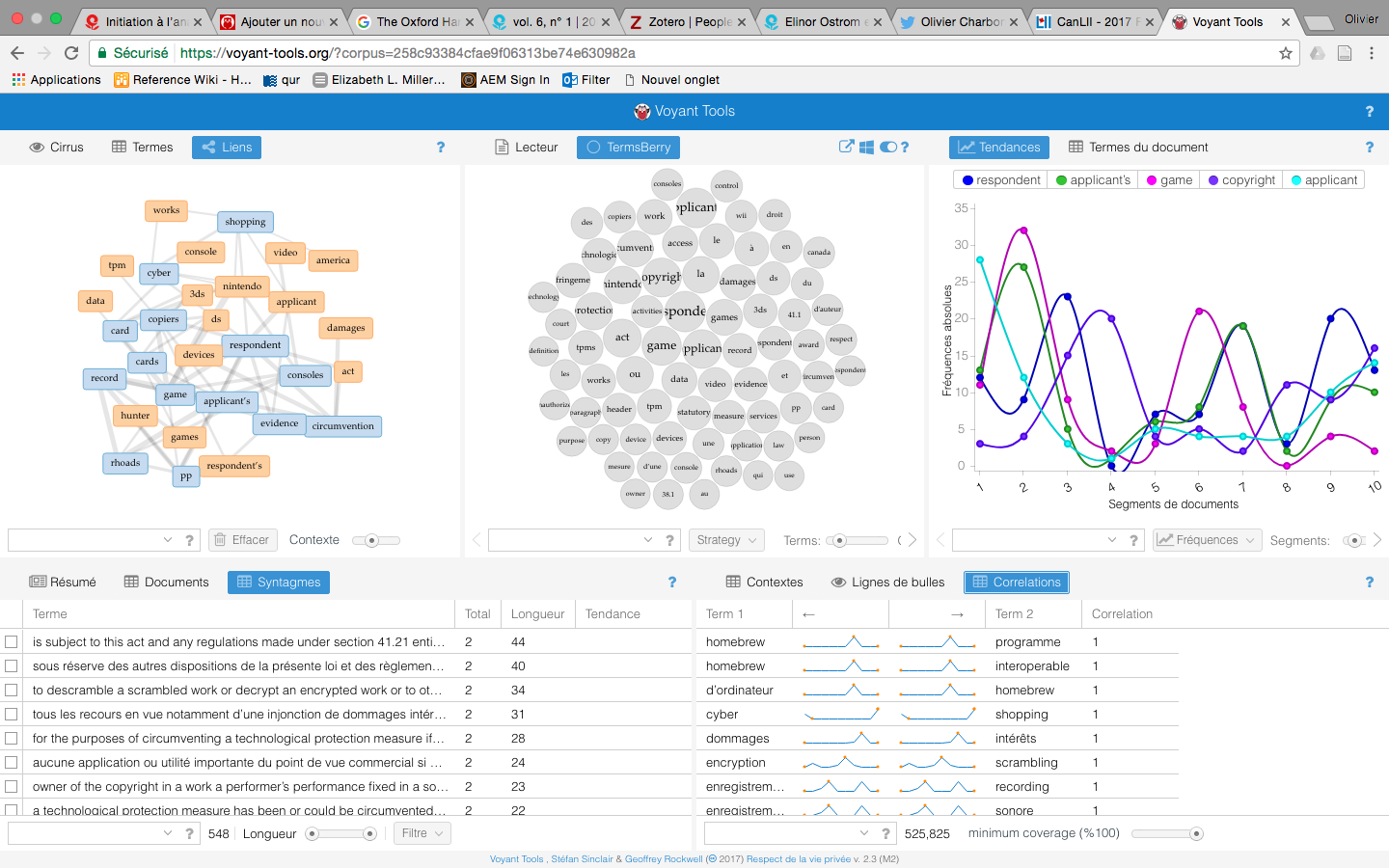
Sur un autre ordre d’idées, j’ai commencé à m’amuser avec un outil de visualisation et d’analyse textuelle conçu au Canada, nommé Voyant-Tools. À juste titre, j’ai pensé à l’utiliser pour analyser rapidement un jugement récent. Par exemple, j’ai copié-collé le texte du jugement de la cour fédéral canadienne opposant Nintendo avec un site de cybercommerce qui offrait des services de contrefaçon: Nintendo of America Inc. v. King, 2017 FC 246 (CanLII), <http://canlii.ca/t/h0r1j>. J’obtiens les résultats suivants sur Voyant-Tools:
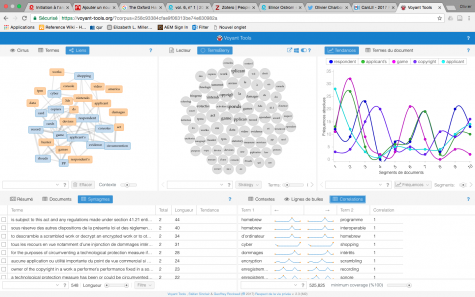
Analyse du jugement Nintendo c. King de la cour fédéral par l’outil d’analyse textuel Voyant Tools
Sans même lire le jugement, il est possible d’extraire rapidement certains éléments pertinents. Il est possible aussi de concevoir des méthodologies d’analyses textuelles nouvelles pour renseigner la pratique du droit et la science du droit…
Si j’ose dire, fut l’un des premiers domaines de la connaissance à saisir l’importance des outils informatiques. Déjà dans les années 1980, les CD-Roms et les premiers outils d’interrogations à distance apparaissaient. La diffusion libre du droit s’inscrit dans se courant. Il faut poursuivre la réflexion quant à l’outil informatique mais en réfléchissant ouvertement à son impact pour la société.
C’est pourquoi je suis ravi de participer à la première École d’été sur l’analyse en réseau à Nice, où je compte explorer comment les outils informatiques, combinées à des méthodes éprouvées en sciences humaines et sociales, peuvent introduire de nouvelles façons de travailler et de réfléchir le droit.