Je me souviens encore de cette paisible journée de février. Une neige cotonneuse saupoudrait mollement Montréal tandis que je lisais mes fils RSS. C’est à ce moment que j’ai appris que Google avait ajusté, le 18 janvier 2009, certains éléments de son algorithme de tri des résultats de recherche de sites web. C’est aussi à ce moment que, selon moi, la société occidentale a basculé à l’ère post-moderne.
À l’époque, l’ingénieur Matt Cutts de Google nuançait la situation comme un ajustement mineur, nommé en l’honneur du membre de son équipe qui a mené l’initiative – le «Vince change» (le changement de Vince). Voir cette vidéo à ce effet :
Il faut dire qu’à l’époque, l’ajustement eut un impact significatif sur les efforts de lissage du référencement (ou, pour nos cousins de France: «search engine optimisation») et fit disparaître beaucoup de petits commerçants des premiers résultats, au profit des sites des grandes marques de commerce. C’est d’ailleurs ce qui demeure aujourd’hui de cette petite modification dans les sources que j’ai consulté… j’ai tenté en vain d’obtenir plus de détails sur le «Vince Change» de 2009 et c’est tout ce que j’ai trouvé. (Oui, j’ai même exploré des articles scientifiques et de la presse professionnelle de l’époque via une banque de donnée spécialisée de ma bibliothèque universitaire)
J’ai le vif souvenir d’avoir appris que depuis le 18 janvier 2009, l’algorithme de tri du moteur de recherche de Google répond aux requêtes avec des résultats optimisés pour l’individu lançant la recherche. Dans la vidéo, l’ingénieur Cutts mentionne que l’algorithme retiens toujours la confiance, l’autorité et la réputation («trust, authority, reputation») comme critères de base pour le tri des résultats. Mais qu’en est-il de cette idée que Google offre des résultats distincts en vertu de la personne effectuant la requête? Il s’agit, selon certains, de la source des chambres d’écho du Web. J’ai également inclus cette perspective dans mon enseignement des habitudes de recherche à mes étudiants.
Donc, j’ai souvenir que le 18 janvier 2009 fut le moment où Google a cessé de retourner les mêmes résultats pour tout le monde avec la même requête. Nous quittons le monde positiviste / naturaliste où une structure (ou ontologie) globale gouvernait le système. Nous entrons un cadre relativiste, pluraliste, personnel. Si le fait et le savoir gouvernent un système soit naturaliste ou positiviste, l’opinion et la croyance s’imbrique dans le relationnel. Ce qui est «vrai» découle donc de son approche épistémique (c’est-à-dire, notre façon de penser dicte notre de comprendre le monde). Cet argument mérite d’être déconstruit, voire amélioré – j’y reviendrai… dans l’intérim, je vous propose cette courte vidéo de mon collègue (et très chic type) Vivek Venkatesh, qui utilise judicieusement la distinction entre la pensée positiviste/naturaliste et relationnelle pour expliquer le racisme systémique sur le site du quotidien Montréalais Le Devoir.
Pourquoi est-ce que je vous parle de tout ceci? Simplement à cause du nouveau livre de Eric Schmidt (ancien grand patron de Google et Alphabet) avec Henry A Kissinger (!) et Daniel Huttenlocher dont le titre est assez évocateur : The age of AI and our human future (l’âge de l’intelligence artificielle et notre futur humain).
Il me semble que la recherche web via Google est un exemple probant de l’impact d’un algorithme apprenant (je déteste intelligence artificielle) sur la société. Il s’agit d’un outil essentiel qui est probablement mal utilisé par la vaste majorité… Simplement car chaque recherche effectuée fait partie d’une longue conversation avec une entité apprenante plutôt qu’un acte distinct. Il faut traiter Google comme la machine qu’elle est, celle qui décide ce que nous pouvons découvrir sur le web en vertu de ce qu’elle sait de nous.
Je vous laisse avec ma vidéo où j’explique, justement, comment entretenir cette conversation à long terme avec votre Google (en anglais, la langue de mon milieu de travail)
#Biblio #Enjeux Félix Trégnier, L’utopie déchue : une contre-histoire d’Internet XVe-XXIe siècle, Fayard, Paris : France, 2019, p. 283-308 (Dans le site Moodle du cours)
La cour vient de livrer son jugement dans l’affaire opposant des auteurs de livres sous droit d’auteur et le géant de la recherche web Google. Ces auteurs s’opposaient au projet « Google Books » où des millions de livres en bibliothèque sont numérisés, indexés et dont de courts extraits sont diffusés par Internet pour répondre aux requêtes des Internautes.
The sole issue now before the Court is whether Google’s use of the copyrighted works is « fair use » under the copyright laws. For the reasons set forth below, I conclude that it is.
Le moteur de recherche propose donc de mesurer la « popularité » de certaines revues savantes en plusieurs langues (voir la liste en Français) en fonction de son «Indice H» :
[Selon Wikipedia] L’indice h (ou indice de Hirsch) est un indice essayant de quantifier la productivité scientifique et l’impact d’un scientifique en fonction du niveau de citation de ses publications. Il peut aussi s’appliquer à un groupe de scientifiques, tel qu’un département, une université ou un pays. […]
Le juge Denny Chin de la cour fédérale de l’État de New York a annulé l’entente « Google Books » entre la multinationale de la recherche web et les représentants des auteurs et éditeurs hier. Le juge précise que l’Addenda de l’entente de Google :
In the end, I conclude that the ASA [the Amended Settlement Agreement (the « ASA).] is not fair, adequate, and reasonable. As the United States and other objectors have noted, many of the concerns raised in the objections would be ameliorated if the ASA were converted from an « opt-out » settlement to an « opt-in » settlement. (See, e.q., DOJ SO1 23, ECF No. 922; Internet Archive Mem. 10, ECF No. 811). I urge the parties to consider revising the ASA accordingly.
The motion for final approval of the ASA is denied, without prejudice to renewal in the event the parties negotiate a revised settlement agreement. The motion for an award of attorneys’ fees and costs is denied, without prejudice. (p.45-6)
Donc, le juge renvoit les intervenants à la table à dessin pour redéfinir les termes de leur entente qui vise la numérisation et éventuellement la commercialisation d’un large corpus de livres.
Du côté de la diffusion libre de l’art, Google propose le Google Art Project. Ce site reprend les fonds de musées de renom pour les diffuser sur la toile. Mais qu’en est-il des droits d’auteurs ?
On s’en doute, une grande majorité des oeuvres sont dans le domaine public (le droit d’auteur étant expiré puisque le créateur original est décédé depuis belle lurette). Il serait possible de les utiliser sans restrictions de droits… mais le site affiche un lien vers les conditions d’utilisation (« Terms of Use« ) génériques de Google. Aucune mention concernant le domaine public. De plus, l’option « copier » n’est pas disponible pour les images.
Comme quoi cette initiative est à l’image des musées ; on regarde sur place, mais on ne touche pas.
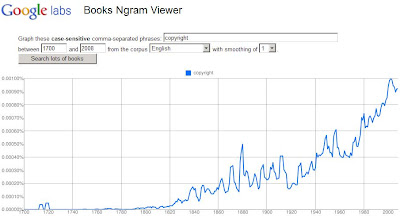
Le New York Times nous apprend que Google, en collaboration avec des chercheurs de Harvard, offre un outil de visualisation unique occurrence de mots dans les livres numérisés. L’outil, nommé Ngram, permet de voir combien de fois un mot apparaît dans les monographies numérisées par le géant d’Internet. Plus de 500 milliards de mots seraient disponibles !
Tel un enfant le matin de Noël, je me suis empressé de lancer une petite requête pour le mot « copyright » qui se trouvent dans les livres en anglais. Voici le résultat :
Hannibal Travis du Florida International University College of Law se questionne sur l’impact des projets de numérisation de masse sur les marchés du livre. Il propose une étude concernant les ventes ou chiffre d’affaire des éditeurs qui s’objectent au Google Book Search et découvre que leurs affaires vont mieux que l’économie en général.
Travis, Hannibal, Estimating the Economic Impact of Mass Digitization Projects on Copyright Holders: Evidence from the Google Book Search Litigation (July 1, 2010). Journal of the Copyright Society of the USA, Vol. 57, 2010. Available at SSRN: http://ssrn.com/abstract=1634126
In Google, we are at once the surveilled and the individual retinal cells of the surveillant, however many millions of us, constantly if unconsciously participatory. We are part of a post-geographical, post-national super-state, one that handily says no to China. Or yes, depending on profit considerations and strategy. But we do not participate in Google on that level. We’re citizens, but without rights.
Although the Google Books Settlement has been criticized as anticompetitive, I conclude that this critique is mistaken. For out-of-copyright books, the settlement procompetitively expands output by clarifying which books are in the public domain and making them digitally available for free. For claimed in-copyright books, the settlement procompetitively expands output by clarifying who holds their rights, making them digitally searchable, allowing individual digital display and sales at competitive prices each rightsholder can set, and creating a new subscription product that provides digital access to a near-universal library at free or competitive rates. For unclaimed in-copyright books, the settlement procompetitively expands output by helping to identify rightsholders and making their books saleable at competitive rates when they cannot be found. The settlement does not raise rival barriers to offering any of these books, but to the contrary lowers them. The output expansion is particularly dramatic for commercially unavailable books, which by definition would otherwise have no new output.