Organisations | Page 5
Écoles
La Puce à l’oreille : balados pour petit.e.s
Olivier Charbonneau 2019-05-08
Je viens de découvrir le site La Puce à l’oreille, un site Québécois qui propose des baladodiffusions pour les enfants, les petits, en libre accès. Je me réjouis de cette initiative de très haute qualité, un travail d’une passionnée et doctorante à l’UQAM, Prune Lieutier.
Bibliothécaire Conférence CultureLibre.ca Droit d'auteur Écoles Enfant Enseignant Exceptions au droit d'auteur Livre et édition Loi ou règlement Québec
Quelques sources juridiques pour le livre numérique en milieu scolaire au Québec
Olivier Charbonneau 2019-05-07
Je prépare une présentation pour le colloque Autour de l’adulte de demain, qui a lieu cette semaine à la Grande Bibliothèque. Voici quelques sources et documents pertinents, autour des grandes thématiques du droit du livre numérique, au delà du droit d’auteur.
Pour débuter, voici une liste de ressources et autres éléments dans l’univers du Gouvernement du Québec :
Copibec propose plusieurs ressources, dont cette liste de pages concernant la Loi sur le droit d’auteur et l’utilisation d’oeuvres en classe.
L’APSDS a produit une Foire aux questions sur le droit d’auteur en milieu scolaire du Québec. J’ai collaboré à ce chantier de l’Association pour la promotion des services documentaires scolaires de 2012 à 2014.
À noter, aussi, dans le domaine général du droit du livre:
Bibliothécaire Droit d'auteur États-Unis Rapport et étude Universités
Une présentation sur les métadonnées juridiques
Olivier Charbonneau 2019-04-26
Intéressant cette présentation de Sara R. Benson et Hannah Stitzlein, deux bibliothécaires universitaires impliquées dans le droit d’auteur, concernant une analyse du recours aux métadonnées juridiques. Elles ont présenté leur étude dans le cadre du congrès annuel de l’ACRL – l’Association of College & Research Libraries (USA), il y a quelques jours. Leur article de 11 pages est disponible dans Internet sous licence CC-BY-SA:
Copyright and Digital Collections: A Data Driven Roadmap for Rights Statement Success
Sara R. Benson and Hannah Stitzlein
Accès libre Gouvernance Information et savoirs Professeur UNESCO
Unir ses forces pour le libre accès
Olivier Charbonneau 2019-04-22
L’UNESCO annonce la création d’une coalition internationale des plate-formes en libre accès d’écrits scientifiques.
At a session organized by UNESCO on 8th April at the WSIS Forum 2019 in Geneva, coordinators of six platforms – AmeliCA, AJOL, Érudit, J-STAGE, OpenEdition, and SciELO Network agreed to join forces to democratize scientific knowledge following a multicultural, multi-thematic and multi-lingual approach. The Global Alliance of Open Access Scholarly Communication Platforms (GLOALL) was launched with a recognition of the principle that scientific and scholarly knowledge is a global public good essential for the achievement of the UN Sustainable Development Goals. The session directly addressed WSIS action line C3 on Access to Information and Knowledge and action line C7 on E-Science.
Source: UNESCO
L’initiative découle d’un panel dans le cadre du programme du Forum du Sommet mondial sur la société de l’information (SMSI, WSIS en anglais) de l’Union international des télécommunications le 8 avril dernier. L’objectif de la rencontre, qui célèbre son 10e anniversaire, consiste à saisir les technologies de l’information et de la communication au service de la réalisation des Objectifs de développement durable. L’initiative GLOALL s’inscrit dans les orientations « C3 » (accès à l’information et la connaissance) et « C7 » (Applications — eScience) du plan d’action du SMSI.
Accès à l'information Internet
Alternatives au moteur de recherche Google
Olivier Charbonneau 2019-03-29
Si vous désirez sortir votre univers web du giron Googlesque, voici quelques alternatives, sans prétention d’avoir analysé leurs dimensions juridico-éthiques :
Accès libre Archives Bibliothèque nationale Conférence Images Logiciel à code source libre Montréal
Quelques réflexions concernant Wikimedia Commons
Olivier Charbonneau 2019-03-26
Hier, j’ai eu l’immense plaisir d’animer une table ronde autour du thème des Usages de Wikimédia Commons dans le cadre de l’exposition « Conrad Poirier. photoreporter (1912-1968) : Valoriser les biens communs du domaine public » au Carrefour des arts et des sciences du Pavillon Lionel-Groulx de l’Université de Montréal, de 13h à 16h.
Avant de poursuivre, je veux expliquer ce qu’est Wikimédia Commons… Tout le monde connaît Wikipedia, l’encyclopédie libre, ouverte, collaborative et organique où n’importe qui peut créer un compte et en éditer le contenu. Wikipedia est l’un des multiples projets de la Wikimedia Foundation, basé en Floride aux USA. Wikimedia Commons est l’un des multiples projets de la Wikimedia Foundation. Il s’agit du dépôt numérique pour des objets pouvant faire l’objet d’une diffusion libre dans Internet. Ainsi, il est possible d’y verser des oeuvres numériques tant que vous possédez des droits suffisants pour le faire. Ainsi, vous pouvez y verser des photos et d’autres objets (mais, en réalité, il fut surtout question de photos).
Donc, parlons de la table ronde d’hier. J’ai compté entre 35 et 40 participants sur place, composé de beaucoup de professionnels de l’information de divers horizons, ainsi qu’entre 15 et 20 participants à distance. Il faut dire que l’un de ces derniers était une classe entière d’étudiant.e.s en technique de la documentation à Trois-Rivières – nous pouvons facilement dire que nous étions probablement près d’une centaines de participants sur place ou virtuellement – un réel succès !
Chacun des trois panélistes disposait de 20 minutes pour présenter son projet, suivi d’une période de question de 10 minutes. Suite à une pause pour visiter l’exposition consacrée à l’oeuvre de Conrad Poirier (qui est dans le domaine public sous l’égide de la Division de la gestion des documents et des archives – DGDA – de l’Université de Montréal) et de précieux biscuits, nous avons discuté de certains thèmes pour la seconde moitié de l’événement.
Lëa-Kim Châteauneuf, bibliothécaire dans le réseau de la Ville de Montréal et Vice-présidente (bénévole) de Wikimedia Canada nous a présenté certaines initiatives personnelles pour enrichir les fonds du projet d’archive ouverte d’objets numérique. Spécifiquement, il s’agit de son projet de recensement de bibliothèques publiques (géolocalisation et photographie des lieux), son projet tapis rouge (pour fournir des photos de québécois.e.s notables à Wikimedia Commons) et de la création d’un pour la prise de photos lors d’événements comme les Salons du livre. Il fut question, entre autres, du processus communautaire de médiation des demandes de retrait de contenu à Wikimedia, le système OTRS ou Open-source Ticket Request System. Léa-Kim nous a également proposé une démonstration du dépôt de deux photos dans Wikimedia Commons suite à la pause.
Florian Daveau est archiviste-coordonnateur à BAnQ dans le Vieux-Montréal (site Viger) et présenté le succès retentissant du versement d’une sélection de photos et documents numériques de la part des archives de BAnQ dans Wikimedia Commons, qui furent visionnées plus de 153 millions de fois ! Florian a touché à plusieurs points, mais j’ai noté en particulier que la décision fut prise de verser uniquement une portion du matériel détenu dans les fonds concernés par le projet de versement. En fait, la décision fut celle des professionnels du projet, afin de concentrer l’attention de la communauté autour d’objets numériques porteurs de mémoire et illustrant la valeur patrimoniale. Outre l’intérêt d’un outil de versement automatisé, cette question de la « quantité » d’objets à versé s’insère dans la stratégie de diffusion afin d’habiliter une communauté à embrasser les objets numériques de nos collections.
Michel Champagne est archiviste à la DGDA de l’Université de Montréal et responsable de l’acquisition et du traitement des archives historiques. Michel nous a présenté les projets de diffusion d’archives historiques des fonds détenus par l’Université de Montréal, surtout par le travail de stagiaires et de la petite équipe de la DGDA. Il fut question du dépôt d’une sélection de photos, où Wikimedia Commons fut positionné comme l’un des multiples vecteurs pour diffuser les archives à l’instar de Flickr, Twitter, Facebook… en ce sens, l’idée de la sélection et l’arrangement des oeuvres à diffuser, qui s’inscrit dans la stratégie globale de diffusion, permet de bonifier l’accès aux archives tout en confirmant la stratégie de diffusion institutionnelle. Par ailleurs, Michel a fait état de guides détaillés pour le versement d’objets numériques, ces guides a suscité un vif intérêt de la salle et nous espérons pouvoir y avoir accès pour partager les acquis de cette équipe innovante suite à cette expérience de diffusion.
Mon rôle fut d’animer la conversation après la pause. J’ai noté certains thèmes qui méritaient, selon moi, d’âtre explorés. En premier lieu, il fut beaucoup question de risques – ceux appréhendés avant la diffusion et ceux qui se sont manifestés. Outre quelques exceptions, il faut noter que la diffusion des archives historiques fut l’occasion de recevoir des commentaires de la communauté afin d’enrichir les métadonnées d’instances. Le scénario catastrophe d’une volée de bois vert ne s’est pas manifestée, la réalité fut bien l’inverse. Il se peut que la judicieuse (pré)sélection des objets à diffuser par des professionnels aurait contribué à cette réception vertueuse et chaleureuse de la part de la communauté.
La réalité fut légèrement différente pour les objets représentant des sujets vivants, ayant dans certains cas demandés le retrait du contenu par le truchement du système OTRS. Sur ce point, les panélistes ont exploré la frontière entre la liberté d’action institutionnelle (lié à la liberté d’expression) dans un contexte où le droit d’auteur ou le droit à l’image du sujet de la photo est en cause. En fait, comment recevoir un refus ou la revendication qui serait contraire à la position institutionnelle concernant le statut du droit d’auteur ou du droit à l’image. Cette zone grise fut le théâtre de beaucoup de réflexions.
J’avais également noté certains autres sujets desquels nous n’avons pas eu le temps d’explorer. Par exemple, comment « mesurer » la visibilité ou l’impact d’un dépôt; comment discuter du rôle des professionnels et des experts vis-à-vis des amateurs et comment animer des communautés autour des objets versés.
Pour tout dire, je crois que le thème du risque fut l’éléphant dans la salle. Nous y pensions tous sans réellement le nommer. L’idée de verser une sélection de contenu en lien avec une stratégie cohérente de diffusion se dégage comme la pièce maîtresse des trois initiatives. Qui plus est, le risque peut se comprendre selon ses diverses éléments, pertinents pour les professionnels de l’information: la légitimité institutionnelle ou professionnelle de la démarche de préservation et de diffusion; l’authenticité et la pertinence du matériel versé par rapport au corpus d’origine et de destination; le statut juridique des objets versés (manuscrits versus publiés) et des sujets (humains) y figurant.
Ce fut une activité riche en perspectives et en réflexions. Merci à Jean-Michel Lapointe de l’UQAM pour l’avoir organisé avec brilo !
Document numérique Voix, données
Répertoires d’outils et données en humanités numériques
Olivier Charbonneau 2019-02-28
BigDIVA, Voyant-Tools, Cytoscape, RStudio… et vous, vous utilisez quel outil pour votre projet en humanités numériques ?
La sélection d’un corpus et d’outils d’analyse s’inscrivent dans les choix des chercheurs sur les plans épistémologiques, conceptuels et méthodologiques. L’univers numérique permet à tout-un-chacun de saisir de nouvelles opportunités de développer son propre cadre de recherche, une sorte d’environnement scientifique personnalisé. Et c’est bien là le problème au niveau (trans/multi/inter)disciplinaire : l’opportunité d’innover de par ses choix de sources et d’outils, quitte à rendre son projet unique, introduit divers glissements quant à la reproductibilité et la transférabilité de ses approches.
Dit simplement, nous vivons à une époque offrant des opportunités inégalées de recherche, au point où nous risquons de prendre de vue l’entreprise collective scientifique qui nous motive.
En ce sens, j’applaudis chaleureusement toute initiative de recensement et de description d’outils et de sources pour des projets en humanités numériques. En voici quelques-uns qui sont passés sous mon nez, n’hésitez pas à en ajouter dans la section commentaire de ce billet:
Open Methods du site DARIAH: un répertoire qui recense les méthodes et outils en humanités numériques. Vraiment intéressant comme catalogue pour des démarches intellectuelles.
DiRT:Directory is a registry of digital research tools for scholarly use.
Isidore, Votre assistant de recherche en Sciences Humaines et Sociales (sources, documents, sujets), surtout de France
De nos amies en Australie, le site HuNi pour les données artistiques et culturelles
Conférence Creative Commons Livre et édition
Assemblée des revues savantes diffusées sur Érudit
Olivier Charbonneau 2018-12-17

Journée d’étude & Assemblée des revues savantes diffusées sur Érudit Lundi 17 décembre 2018 de 9h – 17h,
Chaufferie (CO-R700) du pavillon Cœur des sciences de l’UQAM
Ce matin, j’ai eu l’énorme honneur de prononcer la conférence d’ouverture de la journée d’étude dans le cadre de l’assemblée des revues savantes diffusées sur Érudit.
Je vous propose les liens suivants vers les documents utilisés dans le cadre de ma présentation:
Pour terminer, voici une infographie qui présente le « continuum » du libre accès source: PLoS, How open is it?:
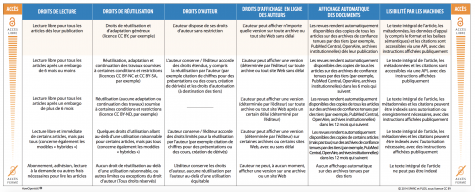
Source: SPARC & PLOS: How Open is it?
Conférence Voix, données
droit + Intelligence artificielle: Conférence Les Cahiers de Propriété Intellectuelle
Olivier Charbonneau 2018-11-23
(BILLET EN COURS D’ÉCRITURE: ÉVÉNEMENT DU 23 NOVEMBRE – MISES À JOUR FRÉQUENTES AUJOURD’HUI)

Programme de la conférence Les Cahiers de Propriété Intellectuelle: droit + Intelligence artificielle
Je vous propose mes notes, j’assiste au colloque intitulé la droit + Intelligence artificielle: Conférence Les Cahiers de Propriété Intellectuelle
Première conférence: IA vue de l’extérieur
Marie-Jean Meurs, Coordonatrice d’HumanIA et Professeure, Département d’informatique (UQAM).
Apprentissage automatique: deux classes d’algorithmes,
- apprentissage supervisé: ensemble d’entrainement ou d’apprentissage; ensemble de test; caractéristiques; hypothèse pour une nième instance suite à l’analyse de l’ensemble test. Capacités de généralisation: quels ensembles d’apprentissage; quelles caractéristiques; quels algorithmes; quels usages => choix humains
- non supervisé: distance, caractéristique des « groupes »
Paul Gagnon, conseiller juridique ÉlémentAI
« La cité de l’intelligence artificielle » dans le MileX à Montréal…
Vu sur twitter ce matin: if it is written in python, it is machine learning; if it is written in powerpoint, it is artificial intelligence
Machines à tisser et le mouvement luddite/saboteur
Ne croit pas que la loi est à la remorque, nous avons le loisir d’anticiper, comprendre, comment le droit va s’arrimer à l’AI
Défis juridiques:
- Anonymisation des données (RGPD) pour utiliser le « moins possible » les renseignements personnels, comparaisons: actuaire doit agir en vertu de limites à l’utilisation de faits dans l’industrie de l’assurance
- RGPD: décision algorithmique, l’humain peut en appeler (transparence algorithmique), défaire la boîte noire technologique pour des raisons juridiques, la loi n’est pas à la remorque
- Droit d’auteur: génération d’oeuvres par des algorithmes; décortiquer les nouveaux cas avec les outils juridiques existants; dichotomie entre l’expression et l’idée
- droit sur les données: ne s’y attendait pas – le rôle des conditions d’accès imposées par les fournisseurs; données ouvertes (CC-BY vs. CC-NC), nuances technologiques qui ont une incidence en droit
Jocelyn MacLure, Professeur titulaire de philo, Université Laval
4e révolution industrielle, société post-travail, statut moral et juridique des agents algorithmiques: inflation sur la réflexion sur l’IA. On a besoin d’une perspective critique (au sens réfléchi, sobre, non-réactionnaire) pour mieux comprendre la situation.
Harari: Homo deus, 21 leçons pour le 21e siècle = révolutions sociales = on doit développer une autre approche
Citation:
Machines will be capable within 20 years to do any work a human can do, Herbert Simon pionnier de l’IA en 1965
Enjeux éthiques importants, il faut considérer les bénéfices
- Rendre la justice plus accessible, efficace, juste
- Santé: bénéfices attendus sont importants mais les risques persistent (ndlr, voir ce texte dans Le Devoir ce matin)
- Accidents de la route
Enjeux éthiques
- responsabilité [civile] des décisions ou actions des agents automatisés, lien de causalité, sommes-nous bien outillés avec les concepts et approches existantes.. concepteur de l’algorithme, l’utilisatrice…
- Transparence des algorithmes, devoir d’explicabilité (sic) et de justification des concepteurs (retracer les étapes de prise de décision pour obtenir un résultat donné, les raisons du jugement de la machine sont inaccessibles surtout en apprentissage profond non supervisé). Probablement l’enjeu éthique le plus important. Cas de Predpol. Cas d’un prêt bancaire. Cas d’une université pour l’admission dans un programme. Cas d’un département des ressources humaines pour faire un premier tri. Cas de charte, de discrimination, droitt à l’égalité des chances => comment opérationaliser le devoir éthique de transparence ? Doit-on imposer un devoir de justifications ? débats en recherches… biais des algorithmes
- Vie privée: texte dans Le Devoir. Droit à l’intériorité, ce droit d’avoir des opinions personnelles et de décider si on les diffuse… si un algorithme prédit mon opinion, contrevient-on à mon « droit d’intériorité »
- Droit du travail: distribution de la richesse, justice au travail, est-ce que nos politiques fiscales et sociales et scolaires sont bien calibrées pour redistribuer les richesses engendrées par l’IA ? Paupérisation exacerbée des démunis.
Réflexion éthique et réflexion avec les juristes et des technologues. Qu Québec: prise de conscience par l’entremise de la déclaration de Montréal sur l’IA responsable, qui sera dévoilée le 3 décembre prochain.
La question qui m’anime suite au panel: les algorithmes sont des outils, vivons nous un moment similaire à l’écriture du code civil au début du 19e siècle: observons-nous un nouveau modèle pour le droit (où ni les juges/précédents, ni un texte-code-autoritaire mais un algorithme stipule le droit) ou simplement l’accélération de ce qu’on fait ? Est-ce que l’accélération mènera à un système juridique homothétique (qui résistera à l’accélération) ou mutera-t-il au delà des systèmes actuels (distinction entre civilisme, common law, droit religieux… lex machina?).
Deuxième panel: IA et PI
Tom Lebrun, doctorant à l’Université Laval
Deux arguments:
- le droit doit tenir compte de l’appropriation des données: apprentissage machine: apprentissage statistique == du déductif à l’inductif (doctrine citée: Dominique Cardon sociologue 2018; Sobel 2017; Mc Cormack 2014; Guadamuz 2018; Shank & Owens 1991) – Jurisprudence: Apple Computer c. Mackintosh Computers 1987; Éditions JCL…. réflexe est de se dire qu’apprentissage machine = appropriation (mais il y a CCH)
- L’IA est un outil. L’auteur qui l’utilise doit être considéré comme titulaire. $ possibilités: IA comme auteur; IA comme travailleur que l’on sollicite; ne connaître aucun auteur; IA comme outil (celle que Lebrun privilégie). Jurisprudence: Geophysical Service Incorporated c. Encana 2016; Thomson c. Robertson 2006. Est-ce que l’oeuvre est suffisamment nouvelle? Cinar c. Robinson 2013;
(Modèle formel d’un neurone artificiel)
Caroline Jonnaert, juriste et doctorante, Université de Montréal
Sujet de thèse: Encadrement des créations par apprentissage profond dans le droit d’auteur; Une image vaut mille «maux»; un outil qui n’est pas comme un appareil photo pour le photographe; les rôles s’inversent
Problématiques en droit d’auteur
- processus créatif (c.f. la présentation de Tom Lebrun)
- résultante créative: réflexion tardive au Canada; consensus étranger autour du régime centré sur l’empreinte créatrice humaine; divers aménagements proposés
Critères: originalité? auteur… humain?
Ouverture sur les constats de Azzaria dans les CPI 30(3)
Réflexion: est-ce que les paramètres des outils constitue une sélection et l’arrangement de faits, qui amène une protection? Quid pour la sélection et l’arrangement du corpus source analysé par l’outil
Louis-Pierre Gravel, avocat chez Robic, brevets
Big data étude d’IBM; percent of time spent processing & collecting data études McKinsey & Bloomberg; The Economist prétend que les données sont la ressource ayant le plus de valeur
(Notions de base en IA) Types d’IA: descriptive; diagnostique; prédictive; prescriptive (prévenir ou reproduire)
Global AIO Talent Report 2018, ElementAI; Indeed.com
Protection par brevet de l’IA (outils ou résultats)
Étude de Warin, Le Duc, Sanger sur les brevets déposés en IA,
- “Mapping Innovations in Artificial Intelligence Through Patents: A Social Data Science Perspective” (Warin, T., Le Duc R., Sanger W.), Proc. Int. Conf. Comput. Sci. Comput. Intell. (CSCI), 2017.
Étude de l’OCDE de 2017 STI Digital Scoreboard : domaines de l’IA. Voir aussi le rapport de (NDLR: 2018 sur les emplois de l’avenir)
Critères pour un brevet: une invention! (ou une amélioration)
- La nouveauté: première du genre
- L’ingéniosité ou rapport inventif; critère de la non-évidence
- L’utilité: fonctionnalité de l’invention
Non-brevetable: découvertes ou théories scientifiques; formules mathématiques; algorithmes
Inventions mises en oeuvre par ordinateur: n’ajoute rien et n’enlève rien à la brevetabilité d’un appareil ou d’un procédé. L’utilisation de l’ordinateur n’est pas suffisante
Deux catégories en IA:
- Avancement dans les technologies de l’IA
- Nouveaux appareils ou procédés faisant appel à l’IA; la vision de l’IA comme outil
Voir le texte de Camille Aubin dans Les CPI 30(3)
Panel 3: IA + droit civil
Nicolas Vermeys, professeur à la Faculté de droit, Université de Montréal
La responsabilité civile: agent autonome; agent intelligent. Col bleu tué dans l’usine Volkswagen; accident avec une voiture autonome
1457 CcQ responsabilité civile: faute, dommage et lien de causalité. Réparer ce préjudice.
Chaîne d’intervenants, 6 individus : Concepteur; programmeur; entraîneur; propriétaire; propriétaire de la base de données; utilisateur
Qui est responsable ? Dépend:
- type d’IA: agent intelligent ou autonome (aspirateur ou voiture?)
- de la qualification de la relation entre l’IA et son utilisateur: propriété, agence/mandat, gardien
Régimes juridiques possibles applicables à l’IA
- Responsabilité pour le fait (autonome) des biens… au Québec, le CcQ 1465: le gardien d’un bien est tenu de réparer le préjudice causé par le fait autonome (nécessite une nouvelle conceptualisation de ce dernier point), absence d’intervention humaine directe; mobilité ou dynamisme… et qui est le « gardien » de l’IA (notions de surveillance et contrôle) parmi les 6 intervenants identifiés
- Accorder la personnalité juridique aux agents autonomes… intelligence? Indépendance/initiative? Accordée à des objets? Refuser la personnalité juridique parce que: pas de patrimoine, pas raisonnable – est-ce qu’une IA est douée d’intelligence? et la raison, un autre niveau… exemple de Rainman.
- Régime inspiré de la responsabilité pour les animaux. Art. 1466. Propriétaire vs. le gardien.
- Régime inspiré de la responsabilité pour les esclaves. Wright c. Weatherly, 15 Tenn. (7 Yer.) 367, 378 (1835)
Quelle approche adopter? Les avocats sont de mauvais oracles (« The blind are not good trailblazers »), cf. juge Easterbrook «Cyberspace and the law of the Horse» (1996) Uni. of Chicago Legal Forum 207
Antoine Guilmain, docteur en droit UMontréal + Paris 1, Fasken
William Deneault-Rouillard (en tandem)
IA + Contrat (excluant la blockchain)
Ça va régler tous les problèmes // Tout ou rien… fausse route
- Nouveaux modèles d’affaires: économie numérique. La donnée est une denrée. Contrat électronique, « I agree » sans lire, diarrhée contractuelle, gratuité et consommation (contrats d’adhésion, légalité), données comme contrepartie contractuelle, consentement…
- Application concrète de l’IA tout au long du cycle contractuel, recherche de co-contractants (marketing comportemental, ajustement de l’offre, embauche et analyse de candidatures), rédaction du contrat, compréhension et formation du contrat (recherche factuelle sur le cocontractant et quantification probabiliste du risque, adhésion: plug-in PrivacyCheck sur les conditions de contrats sur la vie privé ), gestion et analyse des contrats (reconnaissance automatique des types de contrats, recherche algorithmique de contrats….) (outil kira de Fasken), litige et interprétation contractuels (outil predictice), exécution du contrat
- Défis conceptuels: propriété des données (database protection/encryption, data protected by copyright, data protected by trade secrets, data protected by privacy and data protection law) source: R. c. Stewart 1988 – pas de vol car pas de propriété sur données; arrangements contractuels; responsabilité civile contractuelle (multiplicité d’acteurs et attribution contractuelle; exonération art. 1613 CcQ; protection du consommateur; normalisation des contrats – ISO)
Rapport Villany: garder la main
Pierre-Luc Déziel
Dans Les CPI (30)3.
Ce que disent les données lorsque les IA les font parler. Projet « myPersonality » Michal Kosinski
Limite ontologique, opérationnelle (Ewert c. Canada, 2018 SCS 2018), structurelle…
Panel 4: Domaines d’application
Marc Lacoursière (prof AED, U Laval), Ivan Tchotourian (prof ), Ann-Shirley Lebel (étudiante)
Défi de l’encadrement juridique de l’intelligence artificielle dans l’industrie bancaire et des valeurs mobilières
Céline Castets-Renards, prof. Journalisme
Dans Les CPI 30(3)
Outils aidant les journalistes. Outils se substituant aux journalistes. Outils qui rédigent pour les journalistes.
Enjeux:
- Questionnement lié à l’emploi: outils qui rédigent pour le journaliste. Stagiaires, pigistes, jeunes journalistes: quelle nouvelle génération de journaliste?
- Métier même de journaliste: déontologie et professionnels. Vérification des faits, recoupements, interroger les gens, investigation… l’outil peur remettre en cause ces facteurs fondamentaux de la profession. Pluralisme et la diversité des médias, aurons-nous tous les mêmes information, consensuels, convergence de l’information. Protection des sources
- Liberté de la presse, d’information, d’expression. Les outils ne sont pas neutres. Quelles données seront utilisées et par quels systèmes aboutirons-nous aux articles
Transparence algorithmique: pas créé par le RGPD. Art 22 pas de décision automatique algorithmique sans droit d’appel – à lire avec les art. 13 à 15 pour la logique sous-jacente. L’art. 22 n’introduit pas l’explication individuelle. Il faut regarder comment les états ratifient le RGPD. Le texte Français propose un droit à l’explication pour les acteurs publics.
Jie Zhu
Justice prédictive
Data analytics: descriptive / diagnostic analysis => predictive analytics => prescriptive analytics
Droit Internet Standards
Est-il possible de « designer » le droit ?
Olivier Charbonneau 2018-11-05
Le chercheur est souvent appelé à identifier et expliquer ses choix intellectuels. En droit, je considère que le premier exercice réflexif consiste à comprendre à quelle famille intellectuelle l’on s’identifie. Je crois qu’il en existe trois principales familles intellectuelles: naturaliste, positiviste et pluraliste. Les naturalistes considèrent que la source du droit découle de la condition naturelle des humains et s’exprime surtout dans les grandes déclarations à saveur constitutionnelles, comme les droits fondamentaux, etc. Les positivistes considèrent que le droit provient de l’écrit découlant du processus législatif et jurisprudentiel, l’analyse positiviste est un moyen de découvrir le droit édicté. Les pluralistes, quant à eux, considèrent qu’il faut observer les institutions, organisations et agents d’un système socioéconomique pour comprendre le droit qui les gouvernent, bien au-delà de l’ordre régalien.
Personnellement, je suis franchement dans le pluralisme, d’autant plus que les objets qui m’intéressent, les documents et les communautés qui les utilisent, se trouvent plus souvent qu’autrement numérisés. Il est plus pertinent d’utiliser l’outil pluraliste dans ce contexte car j’observe l’émergence de droits via les relations contractuelles.
Il y presque deux ans, j’ai collaboré avec des professeurs en design et en informatique afin de voir si l’on pourrait partir de la théorie pluraliste en droit, comme cadre théorique et conceptuel au sens large, afin d’y greffer une méthodologie en design participatif (participatory design, spécifiquement le requirements engineering approach). Le contexte technologique consiste à identifier des métadonnées juridiques afin de bâtir un système interopérable, évolutif et ouvert dans la chaîne de diffusion culturelle, comme en utilisant des technologies de chaînes de blocs et des algorithmes apprenants. Cette approche peut s’appliquer à divers environnements, comme les bibliothèques ou les réseaux sociaux, où évoluent divers agents et objets à l’étude.
Je suis tombé par hasard sur ces notes et je partage avec vous les sources qui m’ont été suggéré à l’époque, voir ici-bas. Je crois que certaines conceptualisation du droit, surtout celles de l’école pluraliste (systémique, cybernétique, réseaux) permettent aux agents de designer un régime juridique, tout comme elles peuvent co-concevoir un système technologique. Il s’agit, bien sûr, d’un domaine de recherche encore relativement vierge !
Sources:
Muller, M. J. Participatory design: The third space in HCI. In J. A. Jacko and A. Sears (Eds.), The Human Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, Lawrence Erlbaum, Mahwah, NJ, 2002, 1051–1068.
Muller, Michael J., Sarah Kuhn. 1993. Participatory design. Commun. ACM 36, 6 (June 1993), 24-28. DOI=http://0-dx.doi.org.mercury.concordia.ca/10.1145/153571.255960
Vines, John, Rachel Clarke, Peter Wright, John McCarthy, and Patrick Olivier. 2013. Configuring participation: on how we involve people in design. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’13). ACM, New York, NY, USA, 429-438. DOI: https://doi.org/10.1145/2470654.2470716